
SQL Server 2005 分区模板与实例
一、场景
这一段时间使用SQL Server 2005 对几个系统进行表分区,这几个系统都有一些特点,比如数据库某张表持续增长,给数据库带来了很大的压力。
现在假如提供一台新的服务器,那么我们应该如何规划这个数据库呢?应该如何进行最小宕机时间的数据库转移呢?如果规划数据库呢?
二、环境准备
要搭建一个好的系统,首先要从硬件和操作系统出发,好的设置和好的规划是高性能的前提,下面我就来说说自己的一些看法,欢迎大家提出异议;
1) 对磁盘做RAID0(比如3*300G),必要时可以考虑RAID5、RAID10;
2) 使用两张千兆网卡,一张用于外网,一张用于内网(这也需要千兆路由器的配合);
3) 逻辑分区C为系统分区(50G),逻辑分区D为程序安装分区(50G),逻辑分区E为数据库文件逻辑分区;
4) 安装Microsoft Windows Server 2003, Enterprise Edition SP2(x64)操作系统;
5) D盘格式化的时候使用默认分配单元大小,E盘格式为64k分配单元;
6) 安装Microsoft SQL Server 2005(x64)数据库;
7) 在我们网上邻居-本地连接-属性-Microsoft网络的文件和打印机共享-最大化网络应用程序数据吞吐量(勾选上);
8) 运行-gpedit.msc-Windows设置-安全设置-本地策略-用户权限分配-内存中锁定页面-设置用户组(比如Administrators);
9) 运行-services.msc,设置启动类型为手动,并且停止除了SQL Server (MSSQLSERVER)之外的SQL Server服务,除非你对某些服务需要启动,比如作业、全文索引;
10) 设置虚拟内存大小,我通常设置为4096MB-8192MB;
三、前期工作
在进行分区之前,我们首先要分析这个表的数据量(行数)有多少?这个表的存储空间(物理存储)有多少?需要确定分区文件多大为合理?还需要确认我们按照表中哪个字段进行分区?后期的维护是否需要对分区进行管理(比如交换分区进行数据归档等)?
假设我们决定以自增ID作为分区字段(其实应该叫分区数值类型),我们就可以使用上面的行数和存储空间来计算我们的分区边界值了,因为我们确认了分区文件的大小。比如我们表A记录为:1.5亿,占用空间为:700G,如果我们可以接受的文件大小为10G(这个要根据如果需要做交换分区和一些存储空间、硬盘等信息确认的),那么我们的分区值可以这样计算:1.5亿/(700G/10G)≈200W,也就是:200W,400W,600W等等;
分区文件在创建的时候就应该初始化为包含分区边界值数据大小,比如上面的分区文件可以设置为10G,这样就不用重新分配空间了。也可以使用定量增长,比如2048MB。
在设置自增ID为分区字段,那么通常我们会让ID成为聚集索引,而且设置填充因子为100%,这样我们的数据页就不会有空白了。
如果后期的维护需要对分区进行管理,比如交换分区进行数据归档,交换分区是需要索引对齐的,而索引对齐有两种:索引对齐;按存储位置对齐的表。
索引对齐:假如你想让数据与索引分开到不同的文件,可以使用两个不同的分区方案,但是使用同一个分区函数,这样就把索引分开了。(如图1)
存储位置对齐:创建非聚集索引的时候设置【数据空间规范】,两个索引对象可以使用相同的分区架构,并且具有相同分区键的所有数据行最后将位于同一个文件组中。这就叫存储位置对齐。(数据和索引在同一个文件中)(如图2)

(图1)
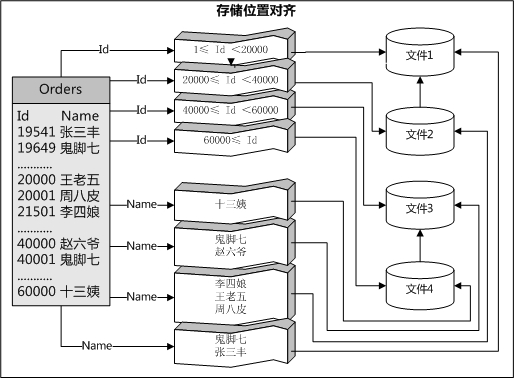
(图2)
四、分区步骤
下面提供了创建分区的代码,其中包括模板还有例子(Ext),这里最主要是注意一些命名规范,希望对大家有用:
步骤1:为MyDataBase数据库创建2个文件组,如果你不想用PRIMARY作为分区,你可以创建多一个文件组,文件组=分区值个数+1;
--1.创建文件组
ALTER DATABASE [数据库名]
ADD FILEGROUP [FG_表名_字段名_分区编号]
--Ext
ALTER DATABASE [MyDataBase]
ADD FILEGROUP [FG_User_Id_1]
ALTER DATABASE [MyDataBase]
ADD FILEGROUP [FG_User_Id_2]
步骤2:为MyDataBase数据库创建2个文件,文件数>=文件组数,一个文件不能属于两个不同的分组中,一个分组可以包含多个文件,注意初始化大小(根据需求)和增长大小(百分比和字节数);
--2.创建文件
ALTER DATABASE [数据库名]
ADD FILE
(NAME = N'FG_表名_字段名_分区编号_data',FILENAME = N'E:\DataBase\FG_表名_字段名_分区编号_data.ndf',SIZE = 30MB, FILEGROWTH = 10% )
TO FILEGROUP [FG_表名_字段名_分区编号];
ALTER DATABASE [数据库名]
ADD FILE
(NAME = N'FG_表名_字段名_分区编号_data',FILENAME = N'E:\DataBase\FG_表名_字段名_分区编号_data.ndf',SIZE = 30720KB , FILEGROWTH = 10240KB )
TO FILEGROUP [FG_表名_字段名_分区编号];
--Ext
ALTER DATABASE [MyDataBase]
ADD FILE
(NAME = N'FG_User_Id_1_data',FILENAME = N'E:\DataBase\FG_User_Id_1_data.ndf',SIZE = 30MB, FILEGROWTH = 10% )
TO FILEGROUP [FG_User_Id_1];
ALTER DATABASE [MyDataBase]
ADD FILE
(NAME = N'FG_User_Id_2_data',FILENAME = N'E:\DataBase\FG_User_Id_2_data.ndf',SIZE = 30MB , FILEGROWTH = 10MB )
TO FILEGROUP [FG_User_Id_2];
步骤3:为MyDataBase数据库创建分区函数,分区值需要根据需求而变化,前面已经做了示范了,这里使用了右分区,关于边界值的理解可以参考:SQL Server 合并(删除)分区解惑;
--3.创建分区函数
CREATE PARTITION FUNCTION
Fun_表名_字段名(数据类型) AS
RANGE RIGHT
FOR VALUES(边界值列表)
--Ext
CREATE PARTITION FUNCTION
Fun_User_Id(INT) AS
RANGE RIGHT
FOR VALUES(100000000,200000000)
步骤4:为MyDataBase数据库创建分区方案,因为前面只创建了2个文件组,所以这里使用了PRIMARY默认的文件组来保存边界值之外的数据,如果你想创建多一个文件组也可以,如下面的Ext1与Ext2;
--4.创建分区方案
CREATE PARTITION SCHEME
Sch_表名_字段名AS
PARTITION Fun_表名_字段名
TO(文件组列表)
--Ext1
CREATE PARTITION SCHEME
Sch_User_Id AS
PARTITION Fun_User_Id
TO([FG_User_Id_1],[FG_User_Id_2],[FG_User_Id_3])
--Ext2
CREATE PARTITION SCHEME
Sch_User_Id AS
PARTITION Fun_User_Id
TO([FG_User_Id_1],[FG_User_Id_2],[PRIMARY])
步骤5:为MyDataBase数据库创建一个名为User的表,这个表有3个字段,Id是自增标识,并在Id字段中创建聚集索引,填充因子为100%,使用上面创建的Sch_User_Id分区方案,创建有不同的创建方式,如Ext1、Ext2、Ext3;
--5.创建表
--Ext1
CREATE TABLE [dbo].[User](
[Id] [int] IDENTITY(1,1) NOT NULL,
[UserName] [nvarchar](256) COLLATE Chinese_PRC_CI_AS NULL,
[Age] [int] NULL CONSTRAINT [DF_User_Age] DEFAULT ((0)),
CONSTRAINT [PK_User] PRIMARY KEY CLUSTERED
(
[Id] ASC
)WITH( PAD_INDEX = ON, FILLFACTOR = 100, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [Sch_User_Id](Id)
) ON [Sch_User_Id]([Id])
--Ext2
CREATE TABLE [dbo].[User](
[Id] [int] IDENTITY(1,1) NOT NULL,
[UserName] [nvarchar](256) COLLATE Chinese_PRC_CI_AS NULL,
[Age] [int] NULL CONSTRAINT [DF_User_Age] DEFAULT ((0)),
) ON [Sch_User_Id]([Id])
GO
CREATE CLUSTERED INDEX [IX_User_Id] ON dbo.[User]
(
[Id]
) WITH( PAD_INDEX = ON, FILLFACTOR = 100, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [Sch_User_Id](Id)
GO
--Ext3
ALTER TABLE dbo.[User] ADD CONSTRAINT [PK_User] PRIMARY KEY CLUSTERED
(
Id
) WITH( PAD_INDEX = ON, FILLFACTOR = 100, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [Sch_User_Id](Id)
GO
步骤6:为User表创建测试数据,这里我就模拟从一个存在的OldUser表中导入数据到分区User表,这里需要注意SET IDENTITY_INSERT 表ON 这个选项;
--6.导入数据
SET IDENTITY_INSERT 表ON
INSERT INTO dbo.表
( [Id]
,[UserName]
,[Age])
SELECT
[Id]
,[UserName]
,[Age]
FROM dbo.[OldUser](nolock) WHERE 条件
SET IDENTITY_INSERT 表OFF
--Ext
SET IDENTITY_INSERT [User] ON
INSERT INTO dbo.[User]
( [Id]
,[UserName]
,[Age])
SELECT
[Id]
,[UserName]
,[Age]
FROM dbo.[OldUser](nolock) WHERE Id <= 1 and Id > 100000000
SET IDENTITY_INSERT [User] OFF
步骤7:当需要查询分区User表记录所处的分区情况时,可以使用下面的SQL;
--7.分区函数的记录数
SELECT $PARTITION.分区函数(字段) AS Partition_num,
MIN(Id) AS Min_value,MAX(Id) AS Max_value,COUNT(1) AS Record_num
FROM dbo.[User]
GROUP BY $PARTITION.分区函数(字段)
ORDER BY $PARTITION.分区函数(字段);
--Ext
SELECT $PARTITION.Fun_User_Id(Id) AS Partition_num,
MIN(Id) AS Min_value,MAX(Id) AS Max_value,COUNT(1) AS Record_num
FROM dbo.[User]
GROUP BY $PARTITION.Fun_User_Id(Id)
ORDER BY $PARTITION.Fun_User_Id(Id);
步骤8:其实到这里实例应该结束了吧?在网上看到的所有关于分区的文章中貌似都是在这里结束了,但是还有一点我需要指出:如果创建存储位置对齐的索引呢?也许通过上面的图2你已经了解了什么是存储位置对齐,如果还不清楚可以查看:SQL Server 2005 中的分区表和索引,其实很简单,如Ext所示,但是主要是理解它的原理和作用;
--8.创建非聚集索引
CREATE NONCLUSTERED INDEX IX_表_字段ON dbo.表
(
字段
) WITH( STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [Sch_User_Id]([Id])
GO
--Ext
CREATE NONCLUSTERED INDEX IX_User_UserName ON dbo.[User]
(
UserName
) WITH( PAD_INDEX = ON, FILLFACTOR = 80, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [Sch_User_Id]([Id])
GO
步骤9:还不想结束?呵呵,这个包含性索引的创建就当是买8送1吧;
--9.创建包含性索引
CREATE NONCLUSTERED INDEX [IX_User_UA_Include] ON dbo.[User]
(
UserName,
Age
)
INCLUDE ([Id])
WITH( PAD_INDEX = ON, FILLFACTOR = 80, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [Sch_User_Id]([Id])
GO
五、注意
上面的代码中我们把文件与文件组是一 一对应起来的,如果我们想更小话文件的话,我们可以在文件组下面创建多个文件,并且设置文件的最大值(MAXSIZE),这样就会把数据分配到不同的物理文件上,但是有一点需要注意,那就是它是一个个的使用文件的,当一个用完了才会使用下一个的。
日志文件也可以像上面的做法来做,这样收缩日志的时候比较方便?删除日志文件比较方便?
有一点我们可能会混淆,那就是既然可以在一个文件组里面创建多个文件,那么这个跟我们按照Id的自增来分布数据是不是等效的?这是有不同的,因为从创建分区方案的时候我们就发现文件组和分区边界值是对应的,所以一段分区值这些数据是分配到以文件组为单位的存储单元中,并不是文件。
补充一下,那就是在文件组下面创建的文件只能按照设置的最大值(MAXSIZE)来区分数据,并不能按照值来区分,这也算一个不同点吧。
六、后记
如果这些表是写的多,读的少:类似记录日志,我们还有一些方案可以进行处理,比如SQL Server 2008的行压缩、页压缩等;比如MySQL的IASM数据引擎;或者是使用MySQL的master/slave负载均衡。
七、参考文献
