
数据库设计 Step by Step (2)
引言:数据库设计 Step by Step (1)得到这么多朋友的关注着实出乎了我的意外。这也坚定了我把这一系列的博文写好的决心。近来工作上的事务比较繁重,加之我期望这个系列的文章能尽可能的系统、完整,需要花很多时间整理、思考数据库设计的各种资料,所以文章的更新速度可能会慢一些,也希望大家能够谅解。
系列的第二讲我们将站在高处俯瞰一下数据库的生命周期,了解数据库设计的整体流程。
 数据库生命周期
数据库生命周期
大家对软件生命周期较为熟悉,数据库也有其生命周期,如下图所示。
 图(1)数据库生命周期
图(1)数据库生命周期
数据库的生命周期主要分为四个阶段:需求分析、逻辑设计、物理设计、实现维护。
这个系列的博文将主要关注数据库生命周期中的前两个阶段(需求分析、逻辑设计),还会涉及反范式化设计的一些内容。如图中高亮圈出的部分。
数据库的物理设计,包括索引的选择与优化、数据分区等内容。这些内容也非常丰富,而且可以自成体系,园子里也有很多好文章,故在本系列中不作主要关注。本文最后将给出一些链接供大家参考。
数据库生命周期的四个阶段又能细分为多个小步骤,我们配合图(1)来看看每一小步包含的内容。
阶段1 需求分析
数据库设计与软件设计一样首先需要进行需求分析。
我们需要与数据的创造者和使用者进行访谈。对访谈获得的信息进行整理、分析,并撰写正式的需求文档。
需求文档中需包含:需要处理的数据;数据的自然关系;数据库实现的硬件环境、软件平台等;
 图(2)阶段1 需求分析
图(2)阶段1 需求分析
阶段2 逻辑设计
使用ER或UML建模技术,创建概念数据模型图,展示所有数据以及数据间关系。最终概念数据模型必须被转化为范式化的表。
数据库逻辑设计主要步骤包括:
a) 概念数据建模
在需求分析完成后,使用ER图或UML图对数据进行建模。使用ER图或UML图描述需求中的语义,即得到了数据概念模型(Conceptual Data Model),例如:三元关系(ternary relationships)、超类(supertypes)、子类(subtypes)等。
eg: 零售商视角,产品/客户数据库的ER模型简图
注:ER图的含义,以及详细标记方法将在该系列的下一篇博文中进行讨论
图(3)阶段2(a) 概念数据建模

b) 多视图集成
当在大型项目设计或多人参与设计的情况下,会产生数据和关系的多个视图。这些视图必须进行化简与集成,消除模型中的冗余与不一致,最终形成一个全局的模型。多视图集成可以使用ER建模语义中的同义词(synonyms)、聚合(aggregation)、泛化(generalization)等方法。多视图集成在整合多个应用的场景中也非常重要。
eg: 集成零售商ER图与客户ER图
零售商ER图如图(3)所示。客户视角,产品/客户数据库的ER模型简图如下:
图(4)以客户为关注点绘制的ER图
注:现在市面上有许多辅助建模工具可以绘制ER图。使用Sybase的PowerDesigner绘制与图(4)相同语义的ER图如下:
其标记法与图(4)中略有不同,这将在今后的博文中加以说明。
这里需要指出的是辅助软件的使用不是设计的核心,大家不要被这些工具迷惑。所以后文中我们将主要使用手绘。只要掌握了ER图的语义,使用这些软件都不会是件难事。
集成零售商ER图与客户ER图
图(5) 阶段2(b) 多视图集成



c) 转化概念数据模型为SQL表
根据映射规则,把ER图中的实体与关系转化为SQL表结构。在这一过程中我们将识别冗余的表,并去除这些表。
eg: 把图(5)中的customer, product, salesperson实体转化为SQL表
图(6) 阶段2(c)转化概念数据模型为SQL表

d) 范式化
范式化是数据库逻辑设计中的重要一步。范式化的目标是尽可能去除模型中的冗余信息,从而消除关系模型更新、插入、删除异常(anomalies)。
讲到范式化就会引出函数依赖(Functional Dependency)这一概念。函数依赖(FDs)源自于概念数据模型图,反映了需求分析中的数据关系语义。不同实体之间的函数依赖表示各个实体唯一键之间的依赖。实体内部也有函数依赖,反映了实体中键属性与非键属性之间的依赖。在保证数据完整性约束的前提下,基于函数依赖对候选表进行范式化(分解、降低数据冗余)。
eg: 对图(6)中的Salesperson表进行范式化,消除更新异常(update anomalies)
图(7) 阶段2(d)范式化

阶段3 物理设计
数据库物理设计包括选择索引,数据分区与分组等。
逻辑设计方法学通过减少需要分析的数据依赖,简化了大型关系数据库的设计,这也减轻了数据库物理设计阶段的压力。
1. 概念数据建模和多视图集成准确地反映了现实需求场景
2. 范式化在模型转化为SQL表的过程中保留了数据完整性
数据库物理设计的目标是尽可能优化性能。
物理设计阶段,全局表结构可能需要进行重构来满足性能上的需求,这被称为反范式化。
反范式化的步骤包括:
1. 辨别关键性流程,如频繁运行、大容量、高优先级的处理操作
2. 通过增加冗余来提高关键性流程的性能
3. 评估所造成的代价(对查询、修改、存储的影响)和可能损失的数据一致性
阶段4 数据库的实现维护
当设计完成之后,使用数据库管理系统(DBMS)中的数据定义语言(DDL)来创建数据结构。
数据库创建完成后,应用程序或用户可以使用数据操作语言(DML)来使用(查询、修改等)该数据库。
一旦数据库开始运行,就需要对其性能进行监视。当数据库性能无法满足要求或用户提出新的功能需求时,就需要对该数据库进行再设计与修改。这形成了一个循环:监视 –> 再设计 –> 修改 –> 监视…。
 在进行数据库设计之前,我们先回顾一下关系数据库的相关基本概念。
在进行数据库设计之前,我们先回顾一下关系数据库的相关基本概念。
这里只做一个提纲挈领的简介,大家可以根据相应的线索进行扩展。
表、行、列
关系数据库可以想象成表的集合,每个表包含行与列。(可以想象成一个Excel workbook,包含多个worksheet)。
表在关系代数中被称为关系,这也是关系数据库名称的起源(不要与表之间的外键关系混淆)。
列在关系代数中被称为属性(attribute)。列中允许存放的值的集合称为列的域(域与数据类型密切相关,但并不完全相同)。
行在关系代数中的学名是元组(tuple)。
关系数据库的理论基础来自于“关系代数”。但在关系代数中,一个集合的各个元组没有次序的概念,在关系数据库中为了方便使用,定义了行的次序。
键、索引
键是一种约束,目的是保证数据完整性
1. 复合键(Compound key):由多个数据列组成的键
2. 超键(Superkey):列的集合,其中任何两行都不会完全相同
3. 候选键(Candidate key):首先是一个超键,同时这个超键中的任何列的缺失都会破坏行的唯一性
4. 主键(Primary key):指定的某个候选键
索引是数据的物理组织形式,目的是提高查询的性能
约束
基本约束
not null constraint, domain constraint
检查约束(Check Constraints)
eg: Salary > 0
主键约束(Primary Key Constraints)
实体完整性(entity integrity),没有两条记录是完全相同的,组成主键的字段不能为null
唯一性约束(Unique Constraints)
外键约束(Foreign Key Constraints)
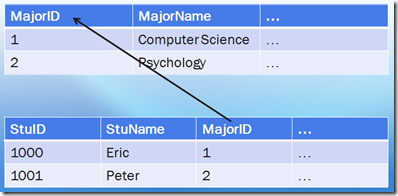
关系数据库操作
1.选择(Selection)
2.映射(Projection)
3.联合(Union)
4.交集(Intersection)
5.差集(Difference)
6.笛卡尔积(Cartesian Product)
7.连接(Join)
上述7种是最基本的关系数据库操作,对应于集合论中的关系运算。
有些书籍中还会加入改名(Rename),除(Divide)等关系操作。
 主要内容回顾
主要内容回顾
1. 数据库生命周期的四个阶段:需求分析、逻辑设计、物理设计、实现维护。
2. 关系数据库的理论基础是关系代数。
数据库物理设计参考资料
第一个链接是我针对查询优化作的读书笔记,后三个链接是SQLServerCentral中几篇关于索引的文章(需要简单注册后才能看到全文)
1. 查询优化系列(查询优化(1),查询优化(2),查询优化(3),查询优化(4),查询优化(5)——总结)
2. Part 1 - The basics of indexes

{kind=link}