
下一个 Transformer 可能又被 Google 做出来了

作者:周一笑
来源:硅星人 Pro
如果把现在的顶尖大模型比作一个人,那它一定患有一种罕见的神经系统疾病:顺行性遗忘症(Anterograde Amnesia)。
这是 Google Research 研究员、最近最受关注的一篇论文《Nested Learning: The Illusion of Deep Learning Architectures》第一作者 Ali Behrouz 抛出的一个让所有人陷入沉思的比喻。
看过诺兰的电影《记忆碎片》(Memento)的人更能理解这种绝望。这种病症的患者拥有完好的“过往记忆”(Retrograde Memory),他们记得发病前的一切,我是谁,我来自哪里,我有什么技能。但对于发病后发生的所有事情,他们永远无法形成“新的长期记忆”。他们只能活在短暂的“当下”,几分钟后,一切就会被重置。
这就是现在 AI 模型的真实写照。
无论 Gemini 或是 ChatGPT 多么博学,如果不联网搜索,它们都只能依靠预训练阶段获得的出厂知识(也就是“发病前”的记忆)来回答问题。而在对话窗口里,无论你教给它多少新公司的业务逻辑,或者纠正了它多少次代码错误,这些信息都只停留在短暂的上下文窗口里。
一旦窗口关闭,或者显存被重置,它就像金鱼一样,把刚才发生的一切忘得干干净净 。下一次见面,它依然是那个出厂时的它,丝毫没有因为与你的交互而变得更聪明一点。
为什么拥有超级算力的 AI,却治不好这个健忘症?
长期以来,行业有一种二元对立的看法,认为 AI 的“架构”(Architecture)和“优化器”(Optimizer)是两个截然不同的物种。
架构是骨架(如 Transformer),它是静态的,出厂即冻结,负责“推理”。“优化器”是雕刻刀(如 Adam、SGD),它是动态的,只在工厂里用来训练模型,出厂后就被没收了。
我们习惯了把 AI 当作一个静态产品,训练好了,打包发布,用户只管用。

但在 Google 最新发布的 52 页硬核论文《Nested Learning: The Illusion of Deep Learning Architectures》(嵌套学习:深度学习架构的幻觉)中,研究团队试图告诉我们,这其实是一种幻觉,是我们人为制造的自我设限。
如果架构和优化器本质上是同一个东西呢?如果并没有所谓的“训练阶段”和“推理阶段”之分,一切都只是不同频率的“记忆压缩”过程呢?
基于这个大胆的假设,Google 团队提出了一个名为 HOPE 的新框架。他们并没有简单地堆砌参数,而是试图从底层逻辑上重构 AI 的“大脑结构”,让它不再是一个出厂即固化的工具,而是在每一次交互中都能微调自己、拥有“快慢记忆系统”的动态生命体。
而这篇论文也被不少人称为“Attention Is All You Need V2”,这篇论文提出的 Transformer 架构成就了今天大模型的火热,而 HOPE 让人们期待它成为下一个 Transformer 级别的创新。
 Ali Behrouz 在 NeurIPS 2025 现场讲解 Nested Learning
Ali Behrouz 在 NeurIPS 2025 现场讲解 Nested Learning
拆解“幻觉”:被遗忘的中间地带
要治好“健忘症”,我们首先得看看现在的 AI 大脑里到底装了什么。
在 Ali Behrouz 的解构下,目前的 Transformer 架构呈现出一种极端的“精神分裂”状态。如果不使用复杂的数学术语,我们可以把它的内部组件看作两个极端:
一个是“极快”的 Attention(注意力机制)。它时刻处于亢奋状态,对你输入的每一个字(Token)都进行瞬时的计算和响应。它的更新频率几乎是无限的,这让模型拥有了所谓的上下文学习能力(In-Context Learning),你刚说的话,它马上就能用。
另一个是“极慢”的 MLP(前馈神经网络)。它是模型的长期记忆库,承载了绝大多数参数。但它的更新频率是 0。这部分像一块冻结的硬盘,除非你耗费巨资进行全量微调(Fine-tuning),否则它永远不会改变。
在这两者之间,存在着一个巨大的真空地带。
这就是“幻觉”的根源。人类的大脑并不是这样工作的。我们的记忆是一个连续的频谱,我们有几秒钟的感官记忆,有几小时的工作记忆,也有几天甚至几年的长期记忆。我们的脑突触并不是非黑即白,而是以各种不同的频率在不断微调。
为了填补这个真空,Google 团队提出了 Nested Learning(嵌套学习) 的概念。我们可以把它想象成一套精密咬合的齿轮系统”:
-
最外层的小齿轮转得飞快(处理当前的对话);
-
中间层的齿轮转得稍慢(记住过去几小时或几天的任务);
-
最里层的大齿轮转得极慢(沉淀世界观和基础知识)。
为了证明这种统一性在生物学上的合理性,他甚至在论文中引用了一个非常硬核的神经科学案例,半球切除术(Hemispherectomy) 。
医学发现,即使切掉人类的一半大脑,通常是为了治疗严重癫痫,剩下的一半脑组织也能通过重组资源,接管几乎所有功能,人依然能正常生活。这说明大脑并没有什么“专门负责 Attention 的模块”或“专门负责 MLP 的模块”,神经组织是通用的、可复用的。
同样的道理,AI 的“架构”和“优化器”本质上也是同一种东西,只是处于不同的嵌套层级:
-
传统的模型记忆的是“数据”(Token);
-
优化器(如 Adam)记忆的是“梯度”(Gradient)。即“我上次在这个地方犯了错,下次要修正” 。
既然都是在“记忆信息”并“更新状态”,为什么我们要把它们人为地割裂开来?也许我们不需要在这个二元对立的框架里修修补补,可以直接设计一个全频率覆盖的动态系统。
HOPE 的三层设计
基于 Nested Learning 的理论,Google 团队交出了一份具体的工程答卷,还起了一个充满寓意的名字:HOPE (High-order OPtimization and Expressivity)。
如果说传统的 Transformer 是一个只有短期记忆的“单核处理器”,那么 HOPE 更像是一个符合神经科学原理的“双重记忆大脑”。它通过两个组件,复刻了类似生物大脑中海马体(Hippocampus)与大脑皮层(Cortex)的协作机制 。
1. 快系统:像海马体一样敏锐的 Titans
在 HOPE 的最前端,是处理即时信息的“快系统”。这里 Google 使用了论文一作 Ali Behrouz 之前的另一项成名作 Titans。
你可以把 Titans 理解为一种“超级 RNN”。它就像人类灵活的海马体,负责快速捕捉和编码当下的新知。传统的 AI 模型在处理新信息时是被动的,但 HOPE 里的 Titans 模块具有极强的“主观能动性”,它是 Self-Modifying(自我修改) 的。
它不仅是在读取数据,更是在根据当前的上下文,实时生成自己这一步学习所需要的 Key、Value,甚至自己决定这一次记忆的 Learning Rate(学习率) 。这意味着,它能敏锐地判断眼前信息的重要性,快速形成短期记忆。
2. 慢系统:像皮层一样厚重的 CMS
这是整个架构中最具颠覆性的设计。HOPE 引入了 Continuum Memory System (连续记忆系统,CMS)。CMS 就像是厚重的大脑皮层,负责将经过筛选的知识长久地刻印在神经元中。
 Google 将人脑电波的频率机制引入了 AI 架构设计,构建了不同更新频率的层级
Google 将人脑电波的频率机制引入了 AI 架构设计,构建了不同更新频率的层级
在 CMS 中,模型内部的 MLP(前馈网络)不再是铁板一块,而是被切分成了不同的层级,就像不同转速的齿轮:
-
高频层: 可能每处理几百个字就更新一次,用于捕捉刚才对话里的新定义。
-
中频层: 可能每处理几万字更新一次,用于适应一个新的项目背景。
-
低频层: 几乎不更新,用于稳固语言的语法和常识 。
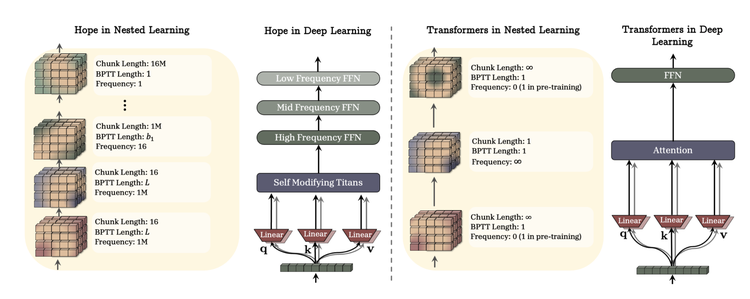
左侧的 HOPE 架构拥有丰富的中间层级
这种设计避免了灾难性遗忘。当新知识涌入时,它会被优先存储在高频层,而不会去惊扰低频层里的旧知识。随着时间的推移,真正重要的信息才会像沙漏里的沙子一样,慢慢沉淀到深层。
3. 优化器也有了“记忆”
Google 的激进之处在于,他们不仅改造了大脑(架构),还改造了老师(优化器)。
为了配合这套复杂的系统,他们设计了一个名为 M3 (Multi-scale Momentum Muon) 的新优化器。
既然模型分了层,优化器为什么不能分层?普通的 Adam 优化器只看眼前的梯度(Local Structure),容易陷入短视。而 M3 优化器本身也被设计成了嵌套结构,它有一层“快动量”负责看脚下的路,还有一层“慢动量”负责看远处的山脉(全局 Loss Landscape)。
这意味着,连负责训练的算法本身,都拥有了更深远的记忆力。
 M3 优化器在 ImageNet 训练任务中,展现出了更快的收敛速度和更低的 Loss
M3 优化器在 ImageNet 训练任务中,展现出了更快的收敛速度和更低的 Loss
实验数据显示,这种设计在 ImageNet 和大语言模型训练上,不仅收敛更快,而且最终效果更好。
4. 给工程师的“后悔药”
对于工业界的开发者来说,HOPE 最迷人的地方可能不是从头训练一个新模型,而是它提供了一种“原地改造”的可能性。
Ali Behrouz 在分享中提到了一个名为 Ad-hoc Level Stacking 的技巧,你不需要抛弃手里现有的 Llama 或 Qwen 模型。你可以直接拿来一个预训练好的模型,人为地将它的不同层指定为不同的“更新频率”,把浅层设为高频,深层设为低频 。
这就像是给一辆已经出厂的旧车,通过刷新固件就解锁了自动驾驶功能。这一特性,让 Nested Learning 成为了一个工程方案。
从“静态产品”到“动态生命”
我们把视角从代码行中抽离出来,会发现 Nested Learning 真正的野心,不在于刷榜,而在于试图完成一次 AI 领域的范式转移。
在 NeurIPS 的分享最后,作者提出了一个发人深省的观点,“深度(Depth)也许不再是唯一的答案。”
过去十年,我们一直在堆叠物理层数,把神经网络做得越来越深。这种暴力美学确实带来了涌现能力,但它也制造了一个巨大的“幻觉”,误以为智能来源于静态的深度。而忽略了真正的深度可能来自于嵌套的优化。
更进一步,论文中提出了一个极其激进的定义:“预训练本身,其实就是一种超长上下文的 In-Context Learning。”
这句话消解了 AI 领域最大的边界。在 Nested Learning 的愿景里,没有所谓的“训练结束”这一天。模型在与用户交互的每一秒,都在以某种微小的频率更新自己的突触。它不再是一个冰冷的、出厂即固化机器,而是一个在数据流中不断呼吸、代谢、进化的有机体。
这或许才是通往 AGI 更本质的道路,智能不是被灌输的,而是在交互中生长的。
当然,任何试图颠覆范式的理论,注定会伴随着巨大的争议。这围绕这篇论文讨论区里,声音很多样。
乐观者将其视为 "Attention Is All You Need V2"。社区对于自我修改这一概念尤为着迷。长期以来,我们一直诟病 LLM 只是“统计学的鹦鹉”,而 HOPE 让 AI 第一次拥有了某种“元认知”能力,即学习如何学习。这种从被动拟合到主动适应的跨越,被认为是 AI 产生质变的关键。
实用主义者则看到了解决灾难性遗忘的曙光。如果这一架构能落地,未来的企业级 AI 将不再需要为了更新一点点业务知识而耗资百万进行全量重训,AI 可以在业务流中自然地学会新规章,同时不忘记旧制度。这是对降本增效是最直接的。
质疑者也大有人在。比如有评论指出,论文中将 SGD(梯度下降)强行解释为“联想记忆”的数学证明虽然精彩,但更多依赖直觉,缺乏严谨的收敛性保障。更有工程师担心,这种复杂的“嵌套优化”会让调参难度呈指数级上升,毕竟,调一个 Adam 已经够头疼了,现在我们要同时调好几个不同频率的“大脑”。
但无论如何,Google 这一次没有在参数量上卷,而是在“学习的本质”上开了一枪。
它用一种近乎哲学的方式提醒我们,对于一个真正的智能体来说,存在就是压缩,活着就是学习。
链接
1)论文链接:Nested Learning: The Illusion of Deep Learning Architectures
2)Google Research 博文:Introducing Nested Learning: A new ML paradigm for continual learning
3)NeurIPS 2025:Nested Learning: The Illusion of Deep Learning Architectures
4)dev.to 博文:Nested Learning — My Reflections on a Model That Learns How to Learn
