
吴军:“ChatGPT不算新技术革命”、“它在中国的热度要远远高于美国”
吴军,毕业于清华大学和约翰霍普金斯大学,计算机专业博士,前 Google 高级资深研究员、原腾讯副总裁、硅谷风险投资人。
【导读】
4 月 3 日晚上,计算机科学家、自然语言模型专家吴军,就人工智能和 ChatGPT 等当下热议的话题作了一次直播分享。
吴军,毕业于清华大学和约翰霍普金斯大学,计算机专业博士,前 Google 高级资深研究员、原腾讯副总裁、硅谷风险投资人。
吴军表示,“我就发现在中国媒体上讨论的热度要远远高于美国”、“这是一件好事,但也是一件坏事。”从区块链、元宇宙再到现在的 ChatGPT,“这些技术实际上是被过度的炒作”。
为何 ChatGPT 没有出现在中国?吴军表示,其“硬件成本就要差不多 10 亿美元”,一般的科研机构做不成,更不用说研究水平的问题。
ChatGPT 的出现,为什么会引起恐慌?
我知道,最近 ChatGPT 这事儿在中国很火,很多人在讨论,但很有意思的是,其实这件事在美国,已经没有太多人去谈论这个话题了。其实不光是 ChatGPT,往前看十年,当时很多新技术出现的时候,我就发现在中国媒体上讨论的热度要远远高于美国。虽然那个技术其实主要出现在美国,但是中国人老百姓对此更关心。我认为这是一件好事,但也是一件坏事。

这个“坏”在于,这些技术实际上是被过度的炒作了,在这个过程中,有很多浑水摸鱼的人从中赚钱。就比如说区块链,当时炒得那么热,但如今这个事已经很少有人讨论了,对吧?这是第一个。第二个就是元宇宙,目前美国只有 Facebook 一家还在坚持做。那到了中国,很多人就在讨论说,我们是不是将来会生活在一个完全虚拟的世界。最后,大概去年底到今年初,Facebook 在这个领域几百亿美元投下去,一个响也没听着,最后开始了大规模的裁员。到了现在,被热炒的一个话题就是 ChatGPT,有的人兴奋,有的人恐惧,还有我现在也看到在中国还有很多人在浑水摸鱼,试图再割大家一次韭菜。
在讲 ChatGPT 是什么以前,我先给大家讲一个历史故事,这历史故事你听起来你就会发笑,但是你回头看,今天很多人的表现也是如此。
1503 年,哥伦布的儿子记下来的这么一件事儿,哥伦布往西航行,去往新大陆,结果航行到中途,到了牙买加这个地方,船上就没吃的了。于是,哥伦布和船员只能寄希望于当地人来提供饮食。但是,提供了几天以后,船员就跟当地人发生了矛盾——有些船员偷了当地人的东西,所以当地人就断了饮食的供应。
为了摆脱这个困境,哥伦布想到了一个妙招。哥伦布当时随身带着一本万年历,在日历上标着说某年月日会出现日食、月食等等所有这些信息。哥伦布当时就把当地的部落首领找来,说你们不给我提供食物,已经得罪了上帝,上帝会发怒,月亮就会变红,然后上帝就会把月亮收走。
当然,我们现在基本上都知道,在月全食发生的时候,也就是地球还没有完全挡住月亮的时候,月亮确实是红的,就是我们所谓的“血月”。但是,当时的牙买加人并不知道。结果,到了晚上,牙买加人就发现,月亮果然变红了,然后慢慢地就一点点消失了。当地人就陷入了恐慌,大家纷纷说,上帝要惩罚他们了。
这个部落首领慌忙去求哥伦布,承诺答应哥伦布的所有条件。哥伦布就说,好,我去帐篷里向上帝祷告,让他不惩罚你们,但是我需要一点时间,然后哥伦布就走进了帐篷。其实,进了帐篷之后,哥伦布就是拿着一个沙漏,在看那个计时。
今天咱们有天文学知识,肯定知道月全食的时间,也就会维持大概 48 分钟,到时候月亮就会重新出现。但是,这些牙买加人不知道。他们看到的就是,哥伦布从帐篷里出来,月亮也就出来了。然后哥伦布说,这是上帝已经听了我的劝解,答应宽恕你们,但是你们必须要给我们好好地提供食物。所以,当地人千恩万谢,给他们不断提供食物。
这个故事说明什么呢?月全食这件事,它的发生背后自有其原因,但是在人们不知道这个原因的时候,往往只能把这个自然现象归结为一个神的作用。而这个神,本身又是人创造出来的。也就是说,人自己创造一个神以后,然后趴在神的脚下,成为了他的奴仆。
这就是我为什么要给大家开《世界文明史》的课程。
其实这个文明的发展过程,就是人类不断认识自然规律的过程。我们一点点的进步,为的就是让现在的我们不再像当地的土著人那样,盲目地相信一个人向上帝祷告真的可以阻止月亮消失。我们现在知道,在日食月食的背后,实际上是开普勒行星的三定律在起作用,然后在开普勒行星三定律背后是牛顿的万有引力定律。人类搞清楚这个原因以后,对自然就不再仅仅是畏惧了,我们可以利用自然规律做很多很多事情。
ChatGPT 的技术基础是什么?
从历史回到现在,其实 ChatGPT 的情况也差不多,背后是一个叫做语言模型的一个数学模型在发挥作用。换句话说,ChatGPT 的背后是一个数学模型。在今天,这项技术显得很强大的原因主要是三个:
- 第一,它用到的计算量很大;
- 第二,它的数据量很大;
- 第三,今天训练语言模型的方法比以前要好很多。

那么,语言模型是什么呢?或者说它是一个什么时代的产物?
它是 1972 年,由我的导师贾里尼克(Fred Jelinek)带领团队研发的一项技术。具体地讲,是他当时在 IBM 带着人来完成的一项技术,是用来衡量一句话或者一个语言现象有多么的可能产生。那它有什么用?它最初的用处是做的语音识别,后来是做机器翻译,再后来是做计算机问答,也就是我们今天熟悉的回答问题。
当时它就可以做摘要,比如举一个例子,有一篇一万字的文章,那么你怎么摘要出十句话能概括这一篇文章的内容,这对于做这个自然语言处理的人来讲,就是一个数学问题。也就是说,你的条件是什么?条件是这一万个字,然后你想得到的结果是什么?结果可能就是十句话,一百个字。然后这里头有很多种组合,你可以随便挑几个句子,也可以把有的句子拆成两段,把后面那些不太重要的修饰或者形容的部分去掉。然后,你也可以把两个句子合成一个句子,那么你在合成一段文本的时候,这个计算机就会计算一个概率,哪些句子合成在一起的概率比较大,它会按照概率帮你合成。
而我们今天看到的 ChatGPT,就是这个大的语言模型,它就是会挑一个概率最大的、最有可能发生的这样一个文本来给你看。所以总体来讲,ChatGPT 生成结果的过程,是一个用大量的计算资源来计算的过程。它需要非常庞大的数据量来支撑,有很多很多的 GPU。没有这些东西的话,ChatGPT 是做不起来的。
而且今天这个 ChatGPT,其实不光是技术,还有很多人工在背后。他们还雇了一家公司,专门负责审核 ChatGPT 产生的结果。比如说,ChatGPT 产生了一百篇摘要,都挺好,我已经分辨不出来了,那么这些人就负责帮我分辨一下,到底哪一篇更像是准确的摘要。
那实际上,你可以看到,ChatGPT 背后就是一个语言模型,而这一语言模型的技术是 1972 年就已经有了的。到现在,经过了五十年,现在行业内其实大家并不觉得它是一个什么了不得的东西。在此以前,这个语言模型其实已经做了很多的事情。
提到“语言模型”(language model)这个词,最初是由我的导师贾里尼克提出来的。他大概在 1993 年的时候到了约翰霍普金斯大学,我是 1996 年到这个大学,然后成为他学生。那么这个词的中文,也就是你看到的“语言模型”这四个字,则是我在 20 世纪 90 年代的时候发表论文时候创造出来的。那时,只有我们这些圈内的人知道它能做很多事,但是你不会想到说,哎,这个事后来会被热炒。
你可以这样理解,“语言模型”之于 ChatGPT,就相当于开普勒的这个行星三定律之于月食。
“语言模型”诞生之初是什么情况?
那么在发明的当时,语言模型是一个什么情况?
其实,在 20 世纪 90 年代的时候,用简单统计方法得到的模型很不准确。这就相当于,我打个比方,你观察行星,但用的是托勒密的地心说来预测,是很不准确的。所以,那时候我们开始引入了语法、主题、语义的很多信息。然后,这个语言模型就变得很复杂了。复杂之后就又带来了一个很大的问题。
什么问题?
比如,我当时做过一个很复杂的语言模型,这个语言模型当时有多少参数?600 万个参数,就是说,这个语言模型大小基本上按这个参数来定。我那时候做的已经是那个时代能做的最大、最复杂的语言模型了。我当时用的还不是 PC 机,而是 20 台超级服务器,然后大概算了三个月才训练出这样一个语言模型。所以你看,它的计算量是非常大的。那么,第一版 ChatGPT,它用的语言模型参数是多少呢?大概是 2000 亿个参数,大家可以看到这些年的变化。
所以,今天很多人问,ChatGPT 在美国出现了,中国研究机构什么时候能做 ChatGPT?其实,中国的大部分研究机构是做不了的,不是说研究水平的问题,而是因为 ChatGPT 太耗资源。今天的 ChatGPT,可能光硬件的成本就要差不多 10 亿美元,这还没算电钱,所以成本和耗资是非常巨大的。所以,如果开完玩笑,问 ChatGPT 的最大贡献是什么,我倒觉得它对全球变暖是有很大贡献的。
所以,我想说的是,ChatGPT 这件事,它的原理很简单,但是在工程上要想做到,其实是蛮困难的一件事。
计算机擅长回答什么问题?
到了大概 2010 年前后,也就是 13 年前,语言模型能做到什么程度?我给大家看两个例子。这两个例子都是我在 2014 年离开 Google 以前做的。当时我负责的是 Google 的自动问答系统,就是让计算机回答问题。不过因为这个产品是英文的,所以在中文世界基本上没有太露脸。
我给你看一下谷歌回答的一个问题——为什么天是蓝色的,why is the sky blue?
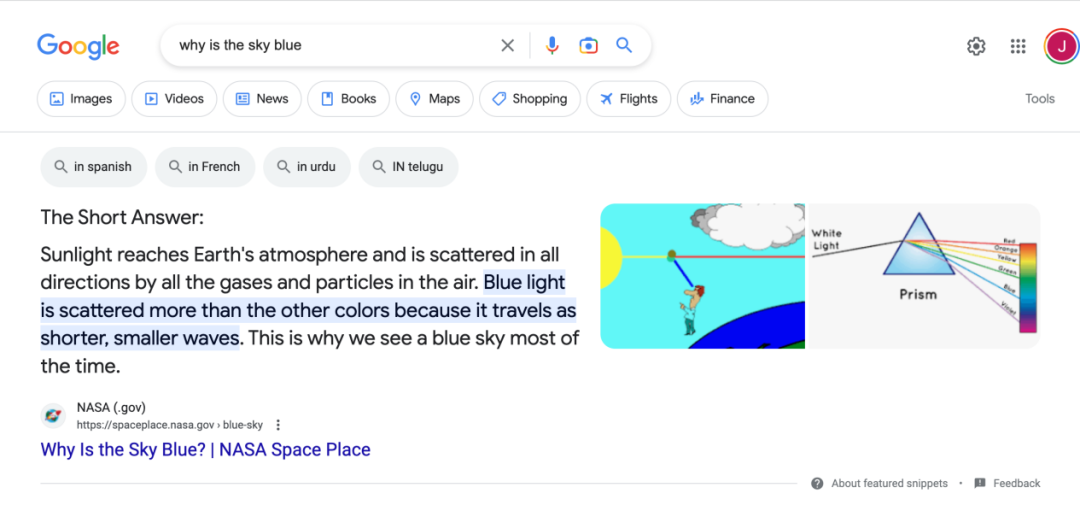
它的回答是这样的:太阳光透过大气层到达地球时会发生折射,空气中的气体会让不同颜色的光散射到各个地方,蓝光波长短,比其他颜色折射率高,所以看上去天是蓝色的。
这是当时计算机产生的一个答案。公平地讲,这个答案比我自己写一段答案写得要更好,因为要解释这现象,你要知道不少物理学知识,而且这个句子看上去也挺合情合理的。而今天人们使用 ChatGPT 的一个目的,就是让他回答问题。
这里面,我给大家做个拆分。
其实,我们问计算机的问题可以分为两类,第一类叫做简单问题,第二类叫做复杂问题。简单问题就是关于事实的问题,比如某某明星是哪儿人,哪一年生的。这都是一些容易的问题,因为它是事实,有明确答案。
第二类是复杂问题,这也是大家觉得 ChatGPT 非常惊艳的地方。它能整合信息,回答天为什么是蓝色的,好像它自己有逻辑一样。再有一个,就是问过程的问题,比如说我怎么烤蛋糕,你能不把一步步写下来?今天我们问 ChatGPT 怎么烤蛋糕,它可以把这个过程给你写得很详细,多少杯水,加多少个鸡蛋,加多少面粉等等,它都可以告诉你。然后你根据它提供的答案,就真能烤出蛋糕,而且烤得可能还挺不错。
这是大家觉得很了不得的地方。但是你要知道,这件事,在 2014 年其实计算机已经做到了,而且做得很好。所以,这项技术本身并没有太多神秘的地方。
计算机和人,谁更擅长写作?
现在,大家热议 ChatGPT,还有一个原因就是觉得它能写作。比如说写一个工作简报,这是今天美国人用 ChatGPT 用得最多的地方。我这周干了 1234567,这七件事,哎,你看我就不用自己费劲地写了,我让 ChatGPT 生成一个,然后再编辑一下子就可以了。
但是,计算机写作这件事,其实你说难也难,说容易也容易,我可以给你举个例子。
在 2014 年我离开 Google 之后,当时不太做编程了,不过那时候我还有一些计算资源,所以我自己在空闲时间会写一些程序,做着玩。当时呢,我就让计算机写了两首诗,大家可以读一下这两首诗。

第一首诗是个五言诗,这是用我的话说,叫做李白风格的一首诗,大家可以读一下。这首诗就是计算机自己写的。实际上,你如果读一读,这个诗里还真有一些李白的这个特点。
那第二首诗,我也把图片放在下面了,你可以看一下。

先说一下,因为古诗都有一说,但是我们现在的读音和当时的读音不一样,所以我们也没去管这个平仄到底合不合古,但是这个我们单从它的内容意境来讲,你读的会觉得很顺畅。
好,那么话说回来。第一首诗怎么做的?
其实再简单不过了,你就把李白的诗放到计算机里。李白诗一共 1000 多首,也就一万来句话,这个对计算机来讲太简单了。它写的时候,就是把句子分拆开来,拆成两个字、三个字一组,比如“空愁”这是一组,“忆长安”这三个字一组。然后它就去拼刚才我讲的语言模型,算概率,哪个概率最大;拆完了以后,我就跟他提一个要求,说要写一首忆长安的诗,它就排列组合,生成出这个《忆长安》,实际上就是这么拼凑出来的。第二首诗稍微复杂一点。
但你知道这两个程序我写了多长时间?两天。这说明什么呢?说明你让计算机写出一些还挺像样的东西,其实不是一件很困难的事情,它没有你想得这么神秘,或者说计算机写作本身没有这你想得这么神秘。
那为什么这两首诗看起来特别好?因为这是唐诗,唐诗的格式是固定的。同样的道理,为什么用 ChatGPT 写周报写得好?因为周报的格式基本上是拉清单,那也是个固定的格式。包括,如果你读《华尔街日报》中文版,这里头我跟你讲,90% 的内容都是计算机写的,只是你不知道。写完了以后人当然要给它一个主题,然后给它写的第一段话写个引子,然后给一个总结,起个标题,这是人要做的。
为什么写财经文章比较好?因为它有好多的事实在里头,格式也是固定的,所以这件事它做起来就很好。
我花这么长时间来讲 ChatGPT 的背景,实际上就是想说它并不神秘,不是一个什么很高深的机器在背后。一方面,ChatGPT 依靠的是一个数学模型,而这个数学模型 1972 年就有了,只是今天它的计算能力非常强,靠蛮力计算。
那么,ChatGPT 训练一次要耗多少电?大概可能是 3000 辆特斯拉的电动汽车,每辆跑到 20 万英里,把它跑死,这么大的耗电量,才够训练一次,这个非常花钱的一件事。
ChatGPT 对我们到底有什么影响?
那么接下来讲讲,ChatGPT 对人有什么影响。
这就要回到历史上来看了,每一次技术革命,其实它对人都会有一些影响。不过,ChatGPT 它不算是一项新的技术革命,因为这我刚才讲了,这个过程很长,从 20 世纪 70 年代到 90 年代,我们做了很多事,90 年代到现在又有很多人做了很多事。这里头最大进步其实不是这个语言模型本身,实际上是后来 2000 年左右产生的深度学习,使得训练语言模型能比以前准确了,不是简单的做统计。
今天训练语言模型早已经不是简单做统计了,这才是 ChatGPT 能产生比较好的结果的一个原因。
至于说 ChatGPT 对人能产生什么样影响,这个问题我先不直接回答你,我先问你,刚才给大家看这两首唐诗,你有没有发现一个什么特点?对了,这两首诗写得不错,但是你原来对唐朝了解,不会因为多了这两首诗会有更新的了解。因为,ChatGPT 它某种程度上有点像鹦鹉学舌,你先要说一段话,它才能跟着学。它说出来的声音可能很好听,但是它并不提供更多的信息。
今天互联网上 90% 的内容都属于这一类——不提供更多的新信息,也不是原创内容,也不是自己的感悟,无非是东抄抄,西凑凑。目前,抖音、快手这类短视频,我觉得 99% 的内容都属于这一类,没有营养,你读完以后可能觉得挺有意思,但实际上你在上面读了再多,其实对你没有任何帮助。
如果说 ChatGPT 真的威胁到了谁,我觉得威胁到的就是这一类人的工作,就是说这个抖音上头那个做短视频的,或者发布一些内容的,ChatGPT 会做得比他们好很多。你就想这样一件事儿,假设说,有一群人天天把那唐诗三百首里头的句子翻来覆去的捯饬,也能捯饬出一些诗,那么 ChatGPT 捯饬起来肯定比人快得多,所以这项技术会对这一批人会有影响。
那么,什么人不会受到影响?就是内容创造的人不会受影响。
为什么我会这么讲?还记得刚才我说的“为什么是天是蓝色的”这个问题吗?Google 为什么能回答这个问题?
因为在 Google 进行回答的时候,它大概把当时英语几乎所有的像样的句子都做了分析,大概有 1000 亿句英语句子。那么实际上你会发现,在一些大学的网站上和 NASA 的网站上,它就有这个答案,只是我们把它拼拼凑凑,删删减减,就把它挑出来了。但是最早的物理学家做这项研究,把这个道理搞清楚,这个工作是有意义的,也是 ChatCPT 取代不了的。
所以,ChatGPT 的工作相当于什么呢?举例子,托勒密创造出这个模型以后,那么每过一段时间,他们欧洲就会编一个大概几十年的一个日历,然后上面标上哪天有日食,哪天行星会怎么运动等等。那么人们根据这些规律,印好多本这个书,这个 ChatGPT 就相当于有好多本书,你拿着以后一看,说,喔,某年月日会发生月食,答案就会很清楚。但是,背后真正有意义的工作不是印这个书,而做托勒密的那个研究。
所以我认为,从历史上看 ChatGPT 其实不算是一次技术革命,它影响到的都是那个比较懒的人,懒得动脑筋,创造新东西的人。真正探索人类知识奥秘的人,是不会被取代的。
ChatGPT 对我们到底有什么影响?
很多人问说,ChatGPT 有什么新机会?坦率来讲,你没机会,因为太耗资源了,你耗不起。那么什么人能够受益?那就是卖资源的这些人。
我可以打个比方,就是说在这个加州淘金热的时候,很多人蜂拥而至,去淘金,单我们到今天为止还不知道哪一个淘金者真的挣得着钱,没一个人把名字留下来。但是最后谁挣着钱了?是卖水的人和卖牛仔裤的人。
ChatGPT 也是一样的道理。大家跟着一起去淘金,其实你是挣不着钱的,但是在过程中,你还不断地要买水喝,买牛仔裤穿,最后就是这两拨人挣到钱了。李维斯 Levi's,就是那时候产生的这么一个公司,它就是做牛仔裤的。
那么最后你可能是给几家大的做云计算的公司在交钱,这可能是一个结果。
好了,讲完了这个 ChatGPT 的历史,我给你做一个简单的总结。
第一,不要恐惧。
今天是很多人恐惧 ChatGPT,就如同不要像当年哥伦布遇到的牙买加土著人恐惧月食,一样的道理。
第二,不要勉强去找所谓的机会,该怎么工作就是怎么工作。
我看有同学问我,说苹果为什么这个不做 ChatGPT,我说这就对了!这就是为什么苹果是世界上最有钱的公司,利润最高,市值最多。目前,很多所谓做这种人工智能的公司到现在都在亏钱。所以,这也是为什么很多同学有时候问很多太不着调的问题的时候,我就开玩笑地问他说,你的房贷还清了吗?你要没还清,你就好好回去工作,把工作做好,这才是对大家最有意义的事情,从历史上看也是如此。
第三,你要识破这些所谓的阴谋家或者想割你韭菜的人的那些把戏。
就是说,如果再来一个人假装哥伦布说他是神的代表,然后他能祈祷上天能让这月亮出来,你不要信。所以你需要了解 ChatGPT 背后的一些科学原理。最简单的一些原理,像今天我讲的这些,你还是需要有所了解。
注:本文来自吴军博士在“得到”上的分享。
