
运维的本质——可视化
没有比“可视化”更好的一个词能概括运维的本质,而“可视化”又应该分成两部分:可视化的服务交付和可视化的服务度量!
第一部分:可视化的服务交付
早期的运维是从ITIL开始的,那个时候大家都不知道运维是什么,幸好找到了一个IT服务最佳实践——ITIL。开始了互联网运维的摸索之路,从CMDB、服务台、事件管理、变更管理、可用性管理、容量管理等逐步去了解,并同步建设对应的管理平台。但我们很快发现,这一完备的流程框架如果遇到了大规模运维的情况,就无法应对,原因在于过多的聚焦于流程以及规范,我们发现很难提升运维敏捷度和精细性,并且我们还是不知道一个完整的IT服务边界在哪儿?如何实现它?
不过在ITIL的实践过程中,其实提出了一个很好的概念——IT服务。对于运维来说,提供一种高效、一致性、透明化、面向用户的服务是运维的价值所在,这样就要求运维屏蔽其提供的服务背后的所有实现细节。
从运维具体事务或者活动的角度来说,如何对其进行一次或者多次的组合封装,把它们变成一个完整的IT运维服务,是此时的运维自动化重点方向。毕竟繁杂的运维事务不进一步封装,对个人或者团队来说,都意味着很高的学习成本和事务执行成本。在传统的IT运维组织中,我们能看到彼此事务之间的割裂非常明显,比如说网络、机房、服务器、应用部署等,都是在不同的团队完成,彼此工作独立进行。在敏捷和精益运维驱动之下,必须要求有一个集成平台来把这些事务流调度起来,否则无法提高事务执行的效率和质量,真正地把运维交付功能变成了交付服务的模式
对于如何封装这些事务或者活动,从DevOps提倡的“自动化一切” (Auto everything)可以找到些答案,其核心的自动化主线就是面向用户的敏捷持续交付。我把持续交付又分成两类场景:一种是持续交付基础设施,一个是持续应用交付(持续构建、持续测试、持续部署、持续反馈),他们有点近似IAAS和PAAS的关系。
持续交付基础设施在公有云IAAS平台中得到很好的解决,利用软件定义计算、存储、网络等技术来实现对上层应用所需资源的快速交付。在私有IT环境中,当前有大量客户采用虚拟机方案或者私有云方案来解决交付难和慢的问题。最新的轻量级虚拟化技术Docker更是热点,根本的原因是把应用的交付在镜像级别完成,从而让应用交付更加快速。
持续交付软件从代码产生的那一刻就开始进行管理,到编译、到测试、到灰度环境验收再到正式环境部署,并且希望这条主线完全自动化。面向程序包的持续集成非常简单,现在有很多的开源解决方案来实现,如Jenkins、Go等,但有一种情况需要特别注意,就是程序包的配置管理问题,这个也往往是影响部署的重要因素。所以我们很多时候使用开源平台只是为了构建程序包,后续包及其其中的配置管理以及实例化部署,特别是大规模集群部署,都是由单独的持续部署平台来解决,而非之前的持续集成工具(虽然它们也支持发布),但持续部署平台需要有和持续集成平台无缝对接的能力。
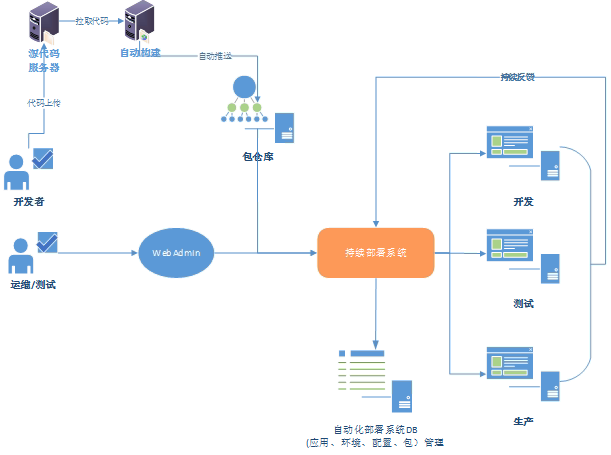
基于软件包的交付解决之后,我们希望交付的粒度更大,如何实现全应用(从应用的前端接入到后端存储)的交付,此时便有了PAAS平台和基于应用架构的可视化部署服务两种方案。这两种实现思路有很大的不同,我们知道完整的PAAS平台提供了对底层公共服务的向上API统一抽象,比如说数据库服务、存储服务、Cache服务。PAAS平台最经典的实现应该是Cloud Foudry了,国内很多PAAS平台基本上都是参考CF来实现的。阿里UC也有一个类似的PAAS平台,示意图如下。
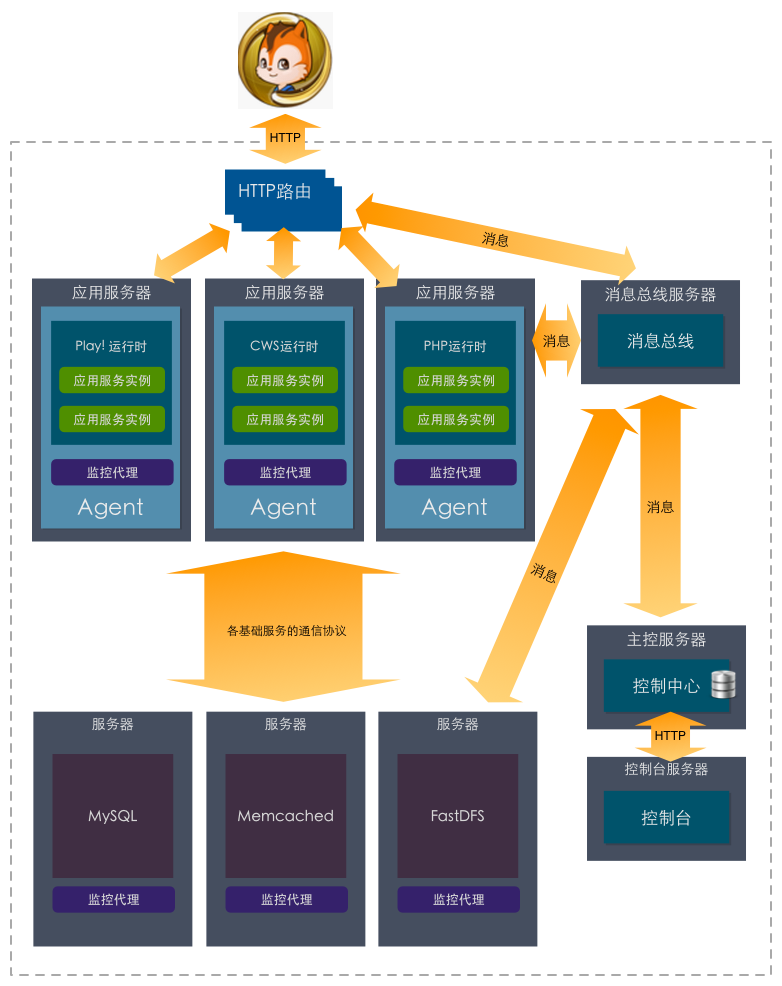
而在现实的情况中,很少公司有能力把Mysql、MC、Fastdfs封装公共服务供上层应用直接调用,意味着对研发程序有着一定的要求,是否还有一种更轻量的无约束自动化方式呢?我们可以把运维的全应用部署转变下思路,此时把应用架构中的各个部分拆解成对象组件(包含属性和状态),比如说机房、OS、应用包等,全应用部署就是这些对象的编排,类似可视化IDE编程环境。
综上所述,运维的自动化最终要实现可视化,复杂的运维工作流必须通过可视化来表达,可视化后的自动化才能让所有人理解一致、执行一致、结果一致。
第二部分,可视化服务度量
“除了上帝,一切人都必须用数据说话”,这是运维人员必须恪守的信条。我写过一篇完整的数据驱动运维的文章“关于数据驱动运维的几点认识”,里面系统地介绍了数据化运维的目的、数据的来源以及如何构建数据体系,等等。
最近也在进行一个数据实践,就是建立面向应用的端到端数据分析体系,该体系对数据有个标准化的分层归类,从基础设施、上层组件、到应用服务、到接口、再到用户侧,基于应用的拓扑架构,收集各类指标,统一到一个分析平台中展现,如下图所示。
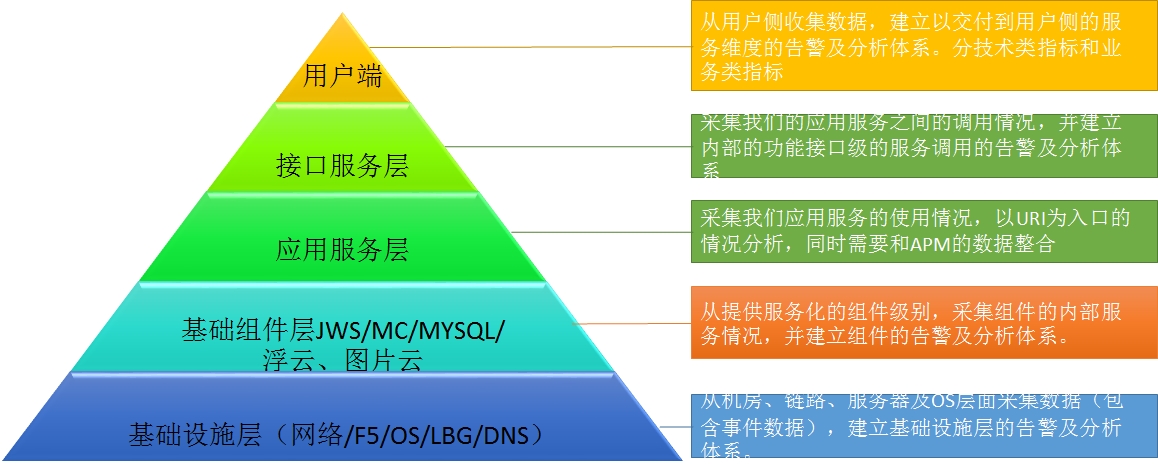
基于这套分层化的数据体系标准,我们也有对应的系统实现,如下图所示。

当形成标准的数据采集、分析和展现体系之后,可以向其他应用不断去复制这套方案,大家只需要遵循一套数据标准即可,最后数据的采集、分析、展现和告警都是标准化完成。这套数据体系建设完成之后,可以在运维的故障定位、服务优化、架构改进、运维规划等各方面找到应用场景。
此时有人会有疑问如何面向应用把这些数据整合关联起来?我们当前是基于配置文件的静态视图和基于接口调用而生成的动态视图来集成。动态调用视图生成会复杂一点,可以让线上的接口调用统一由名字服务中心来接管调度,抽样对接口调用进行染色,从而生成动态的访问关系。
以上视图能快速发现和定位规模故障,但对于单个用户的故障指标上则应对乏力。此时分布式Trace服务的作用就显现出来了,可以借鉴Twitter的Zippkin和Google的Dapper的实现思路。当前我们就结合自身的业务架构特点,实现了一个统一的服务调度框架和名字服务中心,在业务代码无侵入的情况下,可以把业务调度链的染色数据上报和关联,实现对于单个问题的快速定位。
数据的可视化能力非常重要,需要在面向整体和面向某个业务流上都有实现。它首先体现出你对运维的理解是什么样的,从可视化Dashboard上可以看到最直接的运维经验;其次基于可视化之上的数据共享,让大家对数据的理解达成一致;最后利用一致化的可视化数据发挥运维的驱动能力,驱动DevOps,数据的核心价值就在于此。
因此可视化的能力就代表了运维的能力,可视化的程度越高,运维的能力越高。那么你现在到底可视化了哪些运维服务,并能进行度量呢?
