
通过SQL Server Profiler来监视分析死锁
在两个或多个SQL Server进程中,每一个进程锁定了其他进程试图锁定的资源,就会出现死锁,例如,
进程process1对table1持有1个排它锁(X),同时process1对table2请求1个排它锁(X),
进程process2对table2持有1个排它锁(X),同时process2对table1请求1个排它锁(X)
类似这种情况,就会出现死锁,除非当某个外部进程断开死锁,否则死锁中的两个事务都将无限期等待下去。
Microsoft SQL Server 数据库引擎死锁监视器定期检查陷入死锁的任务。
如果监视器检测到循环依赖关系,将选择其中一个任务作为牺牲品(通常是选择占资源比较小的进程作为牺牲品),然后终止其事务并提示错误1205。
这里我们通过SQL Server Profiler来监视分析死锁的发生过程,那样我们就会深刻理解死锁的成因。
1.创建测试表。
在 Microsoft SQL Server Management Studio上,新建一个查询,写创建表DealLockTest_1 & DealLockTest_2两个表:

脚本:
 代码
代码

--创建分析死锁使用到的两个表DealLockTest_1 & DealLockTest_2
go
Set Nocount On
Go
if object_id('DealLockTest_1') Is Not Null
Drop Table DealLockTest_1
go
Create Table DealLockTest_1
(
ID int Identity(1,1) Primary Key,
Name nvarchar(512)
)
if object_id('DealLockTest_2') Is Not Null
Drop Table DealLockTest_2
go
Create Table DealLockTest_2
(
ID int Identity(1,1) Primary Key,
Name nvarchar(512)
)
Go
--插入一些测试数据
Insert Into DealLockTest_1(Name)
Select name From sys.all_objects
Insert Into DealLockTest_2(Name)
Select name From sys.all_objects
Go
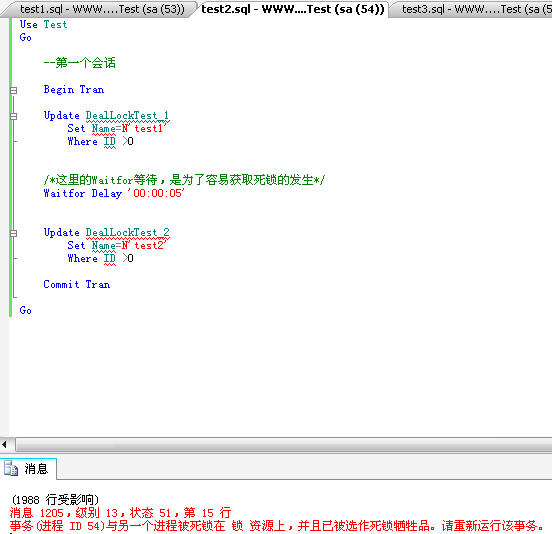
创建好表和插入测试数据后,先执行脚本代码(因为我们不需要跟踪该代码),紧接着,我们就模拟两个会话,一个会话里面包含一个事务。这里我们就新建两个查询,其中第一个会话,是更新DealLockTest_1表后,等待5秒钟,更新DealLocktest_2.

代码
Go
--第一个会话
Begin Tran
Update DealLockTest_1
Set Name=N'test1'
Where ID >0
/*这里的Waitfor等待,是为了容易获取死锁的发生*/
Waitfor Delay '00:00:05'
Update DealLockTest_2
Set Name=N'test2'
Where ID >0
Commit Tran
Go
代码写好后,我们先不要执行代码,接下来就写第二个会话代码; 第二个会话更新表的顺序,刚好与第一个会话相反,是更新DealLockTest_2表后,等待5秒钟,更新DealLocktest_1.

代码
Go
--第二个会话
Begin Tran
Update DealLockTest_2
Set Name=N'test1'
Where ID >0
/*这里的Waitfor等待,是为了容易获取死锁的发生*/
Waitfor Delay '00:00:05'
Update DealLockTest_1
Set Name=N'test2'
Where ID >0
Commit Tran
Go
第二个会话代码,也先不要执行。
2.启动SQL Server Profiler,创建Trace(跟踪).
启动SQL Server Profiler工具(在Microsoft SQL Server Management Studio的工具菜单上就发现它),创建一个Trace,Trace属性选择主要是包含:
Deadlock graph
Lock: Deadlock
Lock: Deadlock Chain
RPC:Completed
SP:StmtCompleted
SQL:BatchCompleted
SQL:BatchStarting
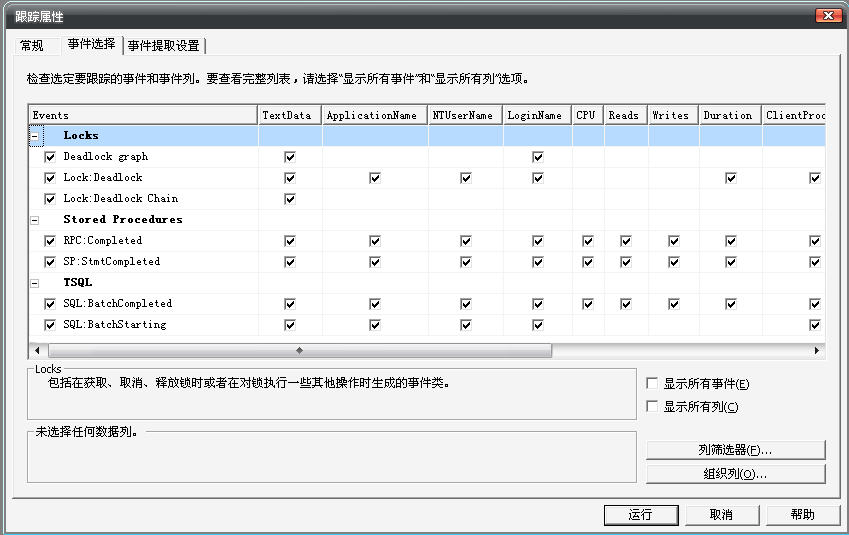
点执行按钮,启动Trace。
3.执行测试代码&监视死锁。
转到 Microsoft SQL Server Management Studio界面,执行第一个会话&第二个会话的代码,稍稍等待5秒钟,我们就会发现其中一个会话收到报错消息
我们再切换到SQL Server Profiler界面,就能发现SQL Server Profiler收到执行脚本过程发生死锁的信息。

OK,这里就先停止SQL Server Profiler上的“暂停跟踪” Or "停止跟踪"按钮,下面我们具体分析死锁发生过程。
4.分析死锁
如下图,我们可以看到第一个会话在SPID 54,第二个会话在SPID 55,一旦SQL Server发现死锁,它就会确定一个优胜者,可成功执行,和另一个作为牺牲品,要回滚。
可以到看到EventClass列中,两条SQL:BatchCompleted事件紧跟在Lock:DealLock后面,其中一条,它就是作为牺牲品,它会被回滚.而另一条SQL:BatchCompleted将会是优胜者,成功执行。
那么,谁是优胜者,谁是牺牲品呢? 不用着急,通过DealLock graph事件,所返回来的信息,我们可以知道结果。
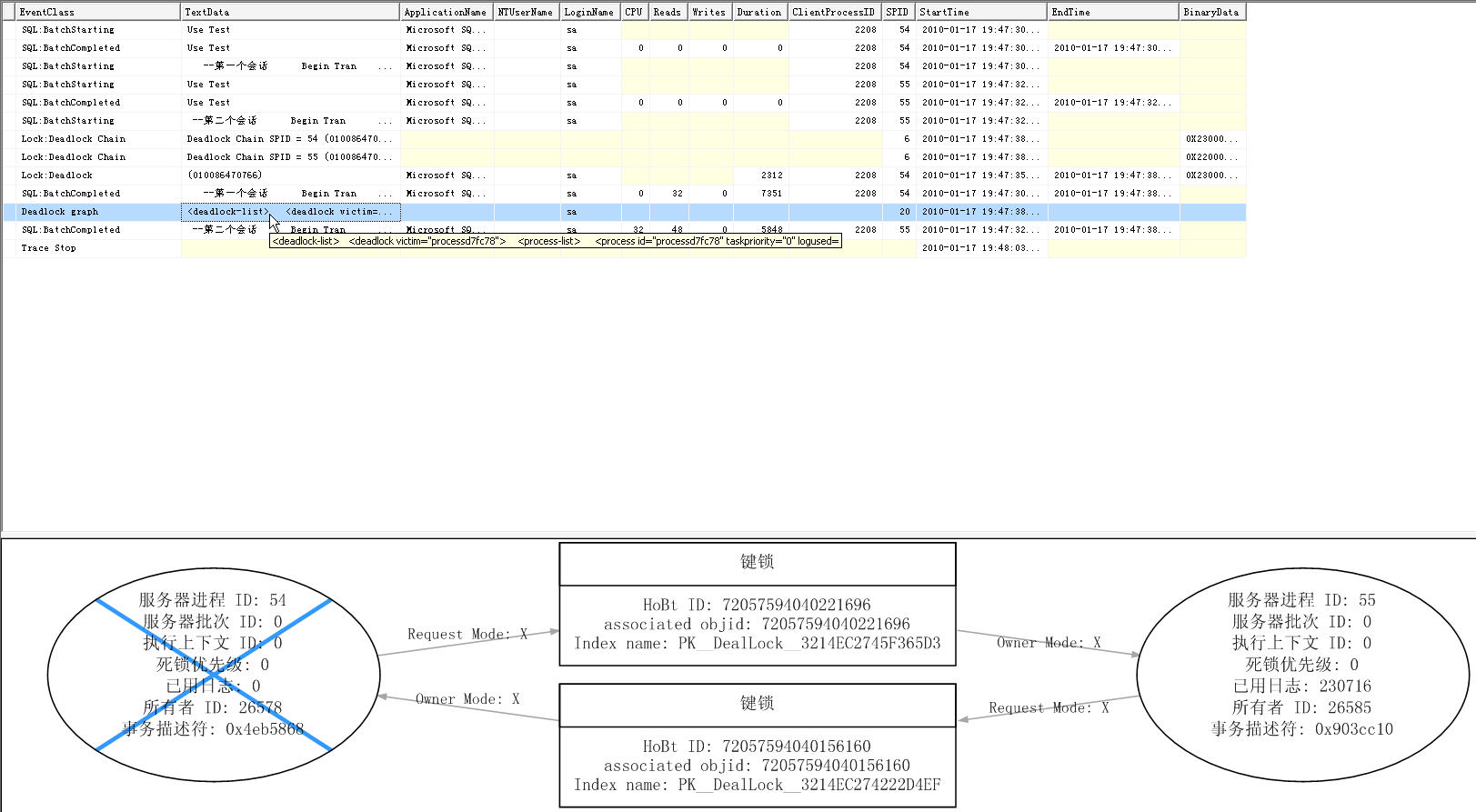
我们虽然不能明白DealLock graph图示的含义,但通过图中描述的关系,我们知道一些有用的信息。图中左右两旁椭圆形相当一个处理节点(Process Node),当鼠标移动到上面的时候,可以看到内部执行的代码,如Insert,UPdate,Delete.有打叉的左边椭圆形就是牺牲者,没有打叉的右边椭圆形是优胜者。中间两个长方形就是一个资源节点(Resource Node),描述数据库中的对象,如一个表、一行或一个索引。在我们当前的实例中,资源节点描述的是,在聚集索引请求获得排它锁(X)。椭圆形与长方形之间,带箭头的连线表示,处理节点与资源节点的关系,包含描述锁的模式.
接下来我们更详细的看图里面的数据说明。
先看右边作为优胜者的这椭圆形,我们可以看到内容包含有:
服务器进程 ID: 服务器进程标识符 (SPID),即服务器给拥有锁的进程分配的标识符。
服务器批 ID: 服务器批标识符 (SBID)。
执行上下文 ID: 执行上下文标识符 (ECID)。与指定 SPID 相关联的给定线程的执行上下文 ID。ECID = {0,1,2,3, ...n},其中 0 始终表示主线程或父线程,并且 {1,2,3, ...n} 表示子线程。
死锁优先级: 进程的死锁优先级有关可能值的详细信息,请参阅 SET DEADLOCK_PRIORITY (Transact-SQL)。
已用日志: 进程所使用的日志空间量。
所有者 ID: 正在使用事务并且当前正在等待锁的进程的事务 ID。
事务描述符: 指向描述事务状态的事务描述符的指针。
这些数据描述,对于我们理解死锁,只需要知道其中的一些就够,除非我们在专门SQL Server机构工作,才可能要深入理解它们。
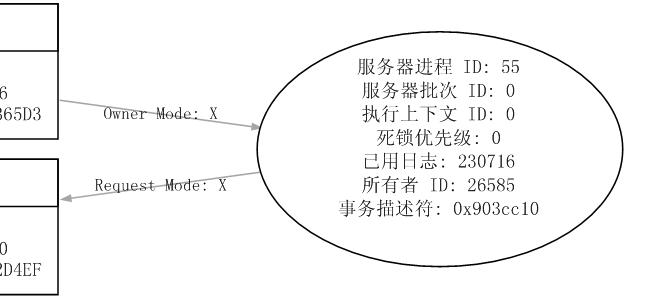
下面我们来看左边作为牺牲品的这椭圆形处理节点,它告诉我们以下信息:
1.它是一个失败的事务。(蓝色的交叉表示)
2.它是作为牺牲品的T-SQL代码。
3.它对右下方的资源节点有一个排它锁(X).
4.它对右上方的资源节点请求 一个排它锁(X).

我们再来看中间两个长方形的资源节点,两个处理节点对它们各自都使用权,来执行它们各自的代码,同时又有对对方使用资源请求的动作,从而发生了资源的竞争。
这也就让我们明白死锁发生的原因。
这里说明下资源节点的一些信息:
HoBT: 堆或 B 树。 用于保护没有聚集索引的表中的 B 树(索引)或堆数据页的锁
associated objid: 关联的对象ID,这里只是索引关联的对象ID.
Index name:索引名

让我们再对SQL Server Profiler监视到的数据,作一次整理:
回顾图:
1.在第3行SQL:BatchStarting, SPID 54 (第一个会话启动),在索引PK__DealLock__3214EC274222D4EF获得一个排它锁,再处理等待状态,(因为在这个实例中我设置了Waitfor Delay '00:00:05')
2.在第6行SQL:BatchStarting, SPID 55 (第二个会话启动),在索引PK__DealLock__3214EC2745F365D3获得一个排它锁,再处理等待状态,(因为在这个实例中我设置了Waitfor Delay '00:00:05')
3.两个进程都各自获得一个排它锁(X),几秒过去,它们就开始请求排它锁。
SPID 54 (第一个会话),先对PK__DealLock__3214EC2745F365D3请求一个排它锁(X),但PK__DealLock__3214EC2745F365D3当前已经给SPID 55 (第二个会话)获得。SPID 54要于等待。
同时,
SPID 55 (第二个会话),开始对PK__DealLock__3214EC274222D4EF请求一个排它锁(X),但PK__DealLock__3214EC274222D4EF当前已经给SPID 54 (第一个会话)获得。SPID 55要等待。
这里就出现了进程阻塞,从而发生死锁。
4.SQL Server 检查到这两个进程(第一个&第二个会话)发生死锁,并对占用资源比较少的进程,列入牺牲品名单,将它终止(Kill)。通过左右椭圆形进程节点显示,可以发现已用日志最少的是左边的进程节点。
5. SPID 54 (第一个会话)被回滚(Rollback),SPID 55 (第二个会话)执行成功。
到这里我们已算完成了,对死锁的监视和分析。
(注:是于其他死锁的定义,死锁模式,死锁避免&预防,等等,不是本文重点,我没有提出,网上太多这方面的文章)
