
如何摆脱令人头疼的架构依赖?
我猜你一定了解以下这种感觉:你马上要准备在某个项目审查会议中发言,而你已知道自己陷入了麻烦中。看看这个仅有5页的幻灯片,你深切地感觉到这个会议注定不会进行得很顺利。即使经过连续三个晚上的通宵奋战,将原本16页的演讲精简为4页的模板,你也无法感觉安心。对于意料之外的技术依赖性所做的任何不稳定性说明都会像一个纸牌屋一样轰然倒塌。而你将因此得到一系列对你的职业生涯有阻碍的资料。接下来的30分钟内,项目总监和她的管理团队将进一步声明:架构师没有完成任何实际的工作。
哪里出了错?
架构师理应了解整个系统与其中的各个元素是怎样联结在一起的,因此这是一个非常重要的角色。但是团队往往无法理解架构依赖中真正的复杂性,等到真正理解的时候,往往已经太迟了。
我有一个同事曾经表示,当代码被共享后,依赖就生产了。“代码共享”的例子包括API、服务规格,以及靠“拷贝与粘贴”方式进行编程。但以上这些并不是依赖产生的所有来源。
架构性依赖的产生是在我们对架构信息——更通用地来说是架构知识进行“共享”时产生的。而在我们创建集成系统时,分享架构知识是不可避免的。这种依赖往往具有很高的复杂性,而且更加难以察觉。
麻烦的地方在于,按照架构的定义,它本身代表了架构元素(例如组件、进程或实体等等)之间的关系。有人可能会争辩说:架构规格本身就是架构级依赖的完整集合了。但是,如果架构的共享是隐式的,即是说我们做出了某些假定,那么危险就会随之产生。而在大规模的企业级环境中,不进行任何假定几乎是不可能的。
难以捉摸的依赖
几年之前,我曾经采访过某个项目团队,他们当时正打算替换一个陈旧的企业级应用程序。该应用程序中的一项核心功能是开发票,经过多年的成长,该公司在这一方面的业务得到了扩展。这种扩展是由外部应用向核心产品应用程序推进的,原因有很多,包括对第三方的支持,以及可维护性等等。
在替换过程中,对于该扩展如何处理旧系统中的货币的四舍五入的策略(例如,如何处理每个计算步骤中的小数),在设计方面的假设正变得逐渐具体化。该扩展的设计者在界面规格的设计上非常小心谨慎,新的应用程序在功能上和技术上都做到了与该扩展的兼容……问题在于,客户发票看起来存在着一些根本的四舍五入错误。
在这里我们学到了很明显的一堂课,即避免对其它系统的工作方式进行任何假设,通过防御式的设计,可以将外部依赖性尽可能降至最低。但不一定总是能做到完全消除以下问题:
- 语义与生命周期:所有的架构元素都会假设某种形式的语义,以及某种隐含的生命周期。这两者很难用界面规格及架构模型进行表达,但却是非常重要的。
- 对相同逻辑元素的多种实现:一旦你的公司决定采购某些现成的打包应用,这种情况就成为不可避免的现实了。
- 手动整合(例如需要通过人工方式将某些数据从某个系统中迁移至另一个系统):这种整合活动在架构模型上往往是不可见的。如果项目团队不打算投入力量开发一个复杂的界面,以实现对相对少量数据的自动转换,那么这种整合活动就会出现。但是人工操作并不能消除依赖。
并不是说封装的概念在这里不起作用了,事实上它依然在发挥作用。但如果我们不能理解横跨多个架构关注面的依赖的影响,也不清楚如何缓解和管理这些依赖,那么问题就会出现。
在上面示例中,有关货币四舍五入的策略就表明架构知识在两个不同的应用中进行了共享。旧应用程序与新扩展中的架构元素各自实现了不同的角色和功能,而“扩展”功能的架构师在这里对旧应用程序中的四舍五入策略进行了某种假设。
换句话说,架构级依赖就是指某个系统(或多个系统)中,在两个或多个元素间产生了架构知识的共享,以允许其中至少一个元素能够被设计、重组、替换或进行操作。
我们可以将这种共享的(在某些情况下是假设的)知识建模为一种抽象的元素,包含两种独立的实现,并将其称之为“共享的元素”。请注意,这种共享的元素与接口的意义是不同的,虽然后者同样也不需要其它应用的某个精准的模型。
为什么“共享元素”难以发现?
在使用传统的依赖分析手段时,我们的技术环境的复杂性会产生至少三种问题:
知识的问题
优秀的架构师会以他所知的最佳知识来定义一个架构,他将这个架构提交给合作者,让专家、业务代表和其他架构师在工作间中进行审查,但在寻找依赖的时候,他们却会遇到三种麻烦:
- 由于架构师对于其它系统的知识有所局限,因此审查者的存在是必要的,但审查者们对于新的系统的了解同样也是有限的。为了让参与者获得足够的共识以发现潜在的依赖,需要进行艰苦的斗争。
- 项目的范围过大,使得架构师很难保持一个单独的视角,这也增加了解决方案产生碎片化的风险 —— 参见观点1。
- 架构师无法描述整个系统的系统,这导致他们只能关注于“已知范围内”的解决方案(这是很自然的)。但众所周知,项目范围定义在依赖的说明方面做的一向很糟糕,依赖不仅仅停留在项目所定义的范围内 —— 请再次参考观点1。
所有这些因素都会影响到审查的过程,最终的结果是架构师们无法正确地提问,至于有关的依赖和相关联的影响是否真正确定下来,一定程度上得看运气如何了。
数据的问题
依赖分析工具通常依赖于源代码或是详细的模型(UML、ArchiMate或类似工具)。在一个异质的技术环境中,要想得到一个几乎完全完整的模型几乎是不可能的。你们有哪位曾经得到过某个整合系统的精确模型?请举手看看。不,我想这种情况是不可能存在的。这并不是说这些工具没有价值,只是说它们在分析主机系统、ERP和新型网站之间的依赖时起不到什么作用罢了。此外,这些工具倾向于仅对源代码结构进行关注,而对所有不可捉摸的依赖视而不见。
建模的问题
如果依赖在界面规格中是清晰可见的,那么我们还有机会对它进行正确的处理。但如果这些依赖不可见,那情况又会变成怎样呢?诸如UML和ArchiMate这样的建模语言能够让使用者通过两个模型元素之前抽象的“关联”类型或“依赖”链接,捕获到依赖(这些依赖不仅仅是常见的元素至元素之间的关联)的存在。这种功能确实很有用,它让我们能够明确地将依赖进行文档化,不过……那些没有记录下来的依赖就将被人遗忘。
但是,虽然这些功能确实能够建模出两个架构上的元素之间的依赖,但它们并不能够帮助我们详细地了解该元素的依赖具体是在哪一部分。如果我们只是在模型中简单地说,元素“X”依赖于元素“Y”,这不能够表明“X”具体依赖于“Y”中的哪一部分,我们只能假设“X”依赖于“Y”的全部。这就导致了依赖的“放大”,因为“X”或许仅仅依赖于“Y”中的某一个元素(比如说“Y.A”,但这个元素在界面上或许是不可见的。接下来的问题就在于“Y.A”中对应的属性了,换句话说,“Y.A”中的哪些部分是需要对依赖进行建模的呢?
暗示:“Y.A”即是“共享的元素”。
我们又该怎样应对这一问题呢?
最大的挑战在于如何避免“好高骛远”,在整个技术环境中地毯式地搜索各种依赖的存在。我们可以将最初的问题 “我们的新系统会依赖于哪些外部元素?”倒过来问:“在我们的新系统中的哪些元素不是新系统本身能够负责处理的?”
你看到发生什么事了吗?
大洋变成了一个小水坑,更重要的是,你对这个小水坑能够加以控制了。这样一来,就使得依赖的搜索范围大大地减少了,并且相关的知识和数据方面的问题更变得更加容易管理了。
但是,我们为什么要追求对元素的控制呢?
原因在于,如果你的新系统中的某个元素使用了某些数据,或是实现了某种算法,并且因此使得你的系统无法成为企业引用(或称之为“控制拷贝”)的话,那么就说明该元素依赖于某个系统中的其它元素。其中一种情况就是“共享元素”的实现。我们不需要知道那个“其它元素”的具体位置,但已经知道需要管理某个依赖了。这一方法也适用于数据的问题,即我们只需了解我们自己的系统就足够了。
我们依然需要对依赖进行建模,这样才能够与相关的干系人交流该依赖的问题。在理想的情况下,我们可以将共享的元素在自己的架构中进行建模,因为共享元素可以成为系统中的某个抽象元素,而不是实际的设计元素。
我们也不希望被迫对其它系统进行架构建模,因为它不仅增加了我们的工作量,并且也不是我们的交付范围中的一部分。但我们需要表达出我们如何管理由于共享某个架构元素所造成的影响的方法。因此,总的来说,我们需要一种依赖模型,以表达出某个架构依赖的三种组成部分:
- 依赖关系,
- 共享元素,
- 以及依赖管理所必须的策略,例如:我们如何协调共享元素所包含的信息。
为了避免依赖成为严重的问题,第三个部分是相当重要的。在以上那个对货币进行四舍五入的示例中,由于依赖的存在,因此企业应用和它的扩展之间必须进行设计决策的同步。另一种方案是,我们可以通过加入新的功能,让它协调最终结果,而隐藏某些中间的计算过程,以缓解依赖所造成的影响。这两种方案都是有效的,我们或许也需要对依赖进行管理和缓解。
以下部分描述了一种能够支持该方式的建模表示法。
依赖驱动建模
第一个任务是将抽象的“共享元素”关系转化为一种我们可以建模的实体。为了更清晰地说明这一点,让我们考虑一下下面这个示例:某个“Person”实体与“Company”实体是相互分离的,但如果这个人受雇于这家公司,那么我们就能够创建一个关系,其中包括了自有的属性。我们可以将这个实体建模为“Staff”。
“Staff”现在能够表达两种含义:1) “Person”和“Company”之间的一种关系,并且这种关系与Person和Company本身的建模是无关的,2) 一系列特定于该关系的属性,例如employment id, salary,office location,role等等。这些属性对于理解必须的依赖管理是非常重要的。比方如,如果该员工不了解工资、工作地点和职位,他是不太可能继续在这家公司打工的。
“Staff“表现了依赖中共享元素的角色
依赖关系
根据Callos等人在这篇论文中的内容所说,基本的架构依赖类型共分两种:即结构型依赖和行为型依赖。结构型依赖包括了软件包、服务或其它类型的API之间的链接,而行为型依赖包括了界面验证逻辑,或是以上的示例中所说的货币四舍五入策略。我们可以将这两个基本的依赖类型与共享元素相结合,正如下图中所描绘的那样。

共享元素通常来说是数据和处理元素的聚合体,但在最抽象的形式中,共享元素也能够涵盖对架构模式、策略或其它依赖的引用。而对其它依赖的引用使得传递性依赖的建模成为可能。
元素的边界展示了每个架构视图或风格的选择范围。元素视图能够帮助我们确定必须进行管理的部分(例如必需的共享元素协调)。举例来说,一个功能性视图需要对功能性设计信息进行协调,而一个组件-连接器视图则需要对通信配置(例如web service资源)进行管理。如果想更多地了解有关架构视图和风格的内容,Clements的著作《软件构架楄档》是一个很好的起点。
一个共享元素也许是可见的,也许不是。元素“D1”或许能“看到”元素“D2”对于共享元素的定义(“外部的”),或许不能(“内部的”)。我们假设D1处于可控设计范围之内,而D2则在范围之外。举例来说,一个数据查询API属于外部的(结构型)依赖,而相关的数据验证规则表现了内部的(行为型)依赖。正是结构型、行为型依赖类型与外部、内部共享元素的组合,形成了依赖的分类,正如下图所示。
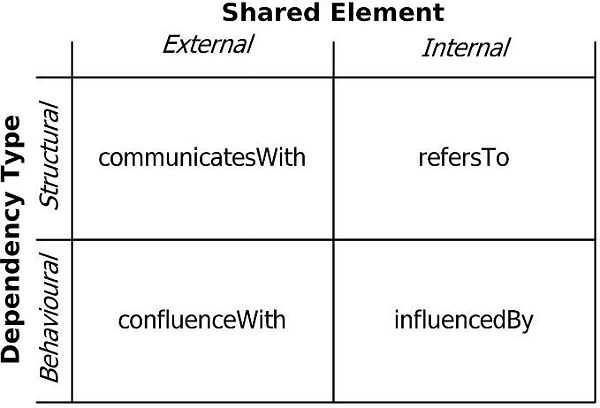
为了完善整个依赖模型,我们将使用抽象的依赖类型“dependsOn”作为这四种依赖类型的超类。
依赖分类
总的来说,一共有以下五种依赖关系类型的存在(SE表示共享元素):
- “dependsOn”:D1依赖于D2,这种依赖有可能是未知的,也可能是多种类型的依赖。我们将其表示为D1 dependsOn(SE) D2。
- “communicatesWith”:D1在结构上依赖于D2,这种依赖是一种可见的外部元素。我们将其表示为D1 communicatesWith(SE) D2。
- “refersTo”:D1在结构上依赖于D2,这种依赖是一种隐含的内部元素。我们将其表示为D1 refersTo(SE) D2。
- “confluenceWith”:D1在行为上依赖于D2,这种依赖是一种可见的外部元素。我们将其表示为D1 confluenceWith (SE) D2。
- “influencedBy”:D1在行为上依赖于D2,这种依赖是一种隐含的内部元素。我们将其表示为D1 influencedBy (SE) D2。
对依赖进行建模
为了更实际地表现这种依赖模型,我们假设有一个建议的架构,其中的Web应用服务器(D1)将通过企业服务总线(ESB)(如下图所示)与某个库存(Inventory)系统进行通信。我们假设该web应用实现了产品目录和购物车两种功能,他们都需要使用到“产品(Product)”这个实体。
该公司的企业架构将库存(D2)系统推举为所有“Product”实体的控制者。因此web应用就依赖于库存系统对于“Product”的定义,也就是说,“Product”成为了一种共享元素,在三个系统中各有一种不同的实现。
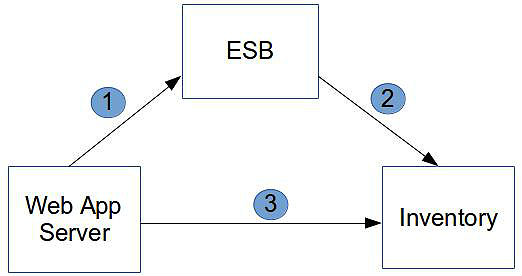
使用前面所提到的分类方式,我们可以定义出以下的依赖:
Web应用服务器(WAS)dependsOn(1,2,3)库存系统,其中:
- WAS communicatesWith(Product) ESB
- ESB communicatesWith(Product) Inventory
- WAS refersTo(Product) Inventory
从WAS架构师的角度来说,她至少要对构架组件-连接器视图进行建模,以表现系统的界面和连接器。该架构师还需要了解WAS的业务需求,基于这些业务需求,她识别出Product实体的以下属性:
- Product Id和分类(category)
- Product描述(description)
- 产品库存量(stock level)
架构师将与库存团队进行交流,并确认了库存系统中所管理的数据确实包括了以上几种所识别出的属性。她也同时发现,产品描述和分类数据对于新的web应用来说并不适用,但她也无法选择忽略这些数据,因为这些数据是新产品中所必需的一部分。这就形成了web应用的内容管理流程中的一个关键组成部分。
产品Id和库存量是仅有的两个通过ESB进行暴露的参数。Web应用需要保持产品Id与库存系统同步。出于内容管理需求的考虑,架构师选择依靠内容管理流程确保产品Id的同步性,而不是实现某种搜索功能。
请注意,到目前为止,我们对这三个系统的说明非常少。但我们已经了解了它们之间的依赖性的重要信息,并根据这些信息提炼出一个简明的系统依赖模型了。
架构师现在就能够对依赖进行精炼了,结果如下:
- Web应用服务器(WAS)dependsOn(1,2,3)Inventory,其中:
- WAS communicatesWith(Product.ID, Product.StockLevel) ESB
- ESB communicatesWith(Product.ID, Product.StockLevel) Inventory
Web应用服务器refersTo(Product.ID, Product.Category, Product.Description, Product.StockLevel) Inventory
这里的关键在于,我们已经将依赖模型转化为一种我们可以使用传统的架构设计技术进行不断地精炼的描述了。并且重要的地方在于,但我们获取了足够的细节信息之后,就可以逐个地停止对这些依赖的精炼过程了。
依赖评估
我们的WAS架构师已经识别出架构依赖中的两个重要部分:即依赖关系和共享元素了。现在,她需要对必需的依赖管理做出决定了。下面的表格概括了已识别出的依赖所造成的架构上的影响。
有趣的是,这张表格对于项目经理来说也是很有价值的,能够帮助他们识别出项目的任务、必需的资源,以及对每个系统的资源分配。每个依赖都需要团队的合作,以所提议的协作。
|
依赖 |
共享元素 |
协作 |
影响 |
|
WAS communicatesWith ESB |
Product.ID, Product.StockLevel |
- 界面规格协议,以调解WAS与库存系统之间的互操作。 - 服务配置管理。 - 用ESB调解界面中特定于位置和技术的属性。 |
如果界面或配置发生了改变,就会产生直接影响。不过,ESB应该隐藏实际的服务URI以及实现技术(实现封装)。 |
|
ESB communicatesWith Inventory |
Product.ID, Product.StockLevel |
同上 |
同上 |
|
WAS refersTo Inventory |
Product.ID |
WAS必须保证产品id与库存系统的同步。这将由内容管理流程负责。 |
如果id不正确,那么web应用需要为用户显示错误信息。 |
|
Product.StockLevel |
对于WAS所发出的某个web service查询请求,将返回库存量信息。不需要明确的协作。 |
假设communicatesWith依赖已经得到管理,则影响不存在。 |
|
|
Product.Category, Product.Description |
产品的分类和描述将通过内容管理流程进行同步。 |
如果内容管理流程出错,则会导致web应用中出现不正确的产品和描述信息。 |
下方的表格概括了适用于某个依赖的一系列评估参数的一种建议,根据架构、项目和通用上下文的不同,参数也应当随之变化,但评估的目的依然保持不变:
- 相关的共享元素属性有哪些?
- 对于每个共享元素属性,我们应当如何缓和与管理依赖(共享元素协作)?
- 如果协作失败,会产生什么样的影响?
|
场景 |
Identifier |
对架构评估场景的简单描述 |
|
依赖 |
Identifier |
某个唯一的依赖Id |
|
分类类型(Taxonomy Type) |
每个分类一种 |
|
|
边界(Boundary) |
元素D1的范围定义,其中D1始终处于设计范围之内,而D2则在范围之外,唯一的例外就是依赖的存在。 The (D1) element(元素) scope(范围) definition(定义), where the D1 element is within the design scope while D2 is outside except only as a dependency |
|
|
协作 |
共享元素(Shared Element) |
对于共享元素和模型的描述(如果存在) Description of the shared element and model if available |
|
特性(Properties) |
相关的共享元素特性列表 The list of relevant(有关的) shared element properties |
|
|
管理(Management) |
对每个共享元素属性的管理(共享元素的协调) The management per shared element attribute(属性) (share element coordination(协调)) |
|
|
影响 |
协作失败时的潜在影响 |
如果共享元素的特性未能正确的进行协作,对于被依赖元素所观察到的影响 The perceived(感知到的) impact to the dependent(依靠的) element, if the shared element properties are not coordinated(调整) correctly |
最后的总结
我希望本文能够帮助你改进对于依赖的判定、评估和通用变更影响的评定。在很多情况下,项目遇到的麻烦都是因为对于技术依赖的疏忽和误解所导致的。但直到目前为止,在对高度复杂的技术环境进行依赖分析时,我们几乎完全依赖于经验丰富的老手的意见。虽然这些意见很有价值,但它们难以复制、交流,并且随着系统规模的成长,也变得越来越不可靠了。
依赖驱动建模是一个良好的工具,它能够让依赖分析更为系统化、可重复,并且更加可靠。重要的地方不在于我们选择了哪一种架构观念,而在于它明确地捕捉到了架构是如何管理依赖的这一点!它的重要性不仅体现在架构的一般质量上,也体现在整个项目计划的质量上。
而依赖驱动建模最优秀的一点在于,它仅仅建立于你所知的内容。你或许刚刚从评审会议上解脱出来。
参考与延伸阅读
- Callo Arias, T. B., van der Spek, P., & Avgeriou, P. (2011). 论文:对于依赖分析解决方案的一种由实践驱动的系统性回顾(A practice-driven systematic review of dependency analysis solutions。 来自《经验主义的软件工程》(Empirical Software Engineering)杂志, 16(5), 544-586.
- Clement, P.; Bachman, F.; Bass, L.; Garlan, D.; Ivers, J.;Little, R.; Nord, R. & Stafford, J (2010). 《软件构架楄档》. ISDN: 0321552687, Addison-Wesley Professional
- OMG (2009). 《统一建模语言第二版》.
- Parnas, D. L. (1972). 文章:将系统分解为模块的标准,来自《ACM交流》, 15(12), 1053-1058.
- The Open Group (TOG) (2009). ArchiMate 1.0 规格。
- Tyree, J. & Akerman, A. (2005). 《架构决策:非神秘化的架构》. IEEE Software, 22(2), 19-27.
关于作者
John Brøndum博士是一位企业架构师,拥有15年以上的项目经验。在2010年,John创建了自己的咨询公司Brøndum Consulting Pty Ltd,以帮助客户设计并交付技术解决方案,为客户的业务创造真正的价值和影响力。John最近在NICTA的支持下,于新南威尔士大学获得了架构依赖建模的博士学位。如果想了解他的更多信息,请访问这个网站。
