
TSQL::(2.1)物理查询数据流
当一个查询到达数据库引擎时,SQL Server执行两个主要的步骤来产生结果。第一步是查询编译,他生成查询计划;第二部执行这个查询计划。
查询编译由三个步骤组成:分析、代数化及查询优化。然后编译器把经过优化的查询计划保存到过程缓存中。然后执行引擎把该计划转换为可执行的形式,然后执行其中的步骤以生成查询结果。如果今后再执行相同的查询或存储过程时,过程缓存已经包含了该计划,则跳过编译步骤,直接重用缓存的计划来执行该查询或存储过程。
安装Northwind数据库,点选“包括实际的执行计划”并执行以下查询:
USE Northwind;
GO
SELECT C.CustomerID, COUNT(O.OrderID) AS NumOrders
FROM dbo.Customers AS C
LEFT OUTER JOIN dbo.Orders AS O
ON C.CustomerID = O.CustomerID
WHERE C.City = 'London'
GROUP BY C.CustomerID
HAVING COUNT(O.OrderID) > 5
ORDER BY NumOrders;
生成结果:
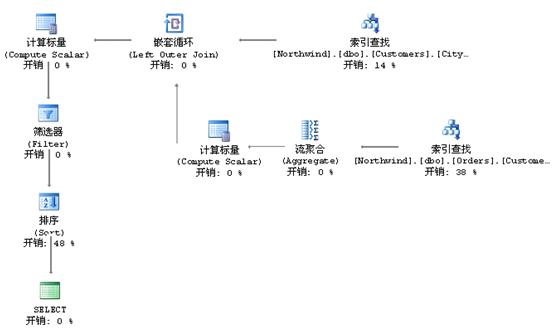
执行计划流程图:
文本形式的执行计划输出:
|--Sort(ORDER BY:([Expr1004] ASC))
|--Filter(WHERE:([Expr1004]>(5)))
|--Compute Scalar(DEFINE:([Expr1004]=CASE WHEN [Expr1004] IS NULL THEN (0) ELSE [Expr1004] END))
|--Nested Loops(Left Outer Join, OUTER REFERENCES:([C].[CustomerID]))
|--Index Seek(OBJECT:([Northwind].[dbo].[Customers].[City] AS [C]), SEEK:([C].[City]=N'London') ORDERED FORWARD)
|--Compute Scalar(DEFINE:([Expr1004]=CONVERT_IMPLICIT(int,[Expr1009],0)))
|--Stream Aggregate(DEFINE:([Expr1009]=Count(*)))
|--Index Seek(OBJECT:([Northwind].[dbo].[Orders].[CustomersOrders] AS [O]), SEEK:([O].[CustomerID]=[Northwind].[dbo].[Customers].[CustomerID] as [C].[CustomerID]) ORDERED FORWARD)
计划中的分支是交叉执行的。该示例中SQL Server交替执行嵌套循环的两个分支。
灰色箭头表示数据流,箭头的粗细表示查询优化器估计通过该连接传递的行数。
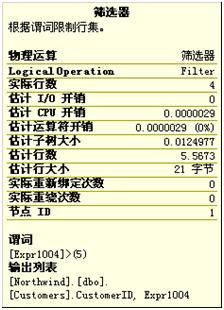
引擎先对Customers表执行索引查找,他将选择来自London的第一个消费者。可以查看此部操作的详细信息,如下图。

可以看到此步的查找谓词的前缀为:
[Northwind].[dbo].[Customers].[City] = N'London
被选择的行被传递到嵌套循环运算符,嵌套循环则会开始进行内层循环的运算。内层循环由计算标量、流聚合、索引查找组成。

查看一下内层循环的第一步,索引查找的详细信息,如下图:

查找谓词的前缀为:
[Northwind].[dbo].[Orders].CustomerId =
([Northwind].[dbo].[Customers].CustomerID as [C].CustomerID)
我们看到C.CustomerID的值被用于查找Orders表以获得该CustomerID的所有订单。也就是说嵌套循环的内侧引用了从外侧得到的值。
紧接着,查询会在找到来自London的第一个消费者的所有订单之后,将这些订单传递给流聚合运算符进行统计。从文本形式的执行计划输出上可以很好的理解流聚合在这里做了什么。
|--Stream Aggregate(DEFINE:([Expr1009]=Count(*)))
其实他就是数了一下,有多少个订单。
然后是计算标量的操作:
|--Compute Scalar(DEFINE:([Expr1004]=CONVERT_IMPLICIT(int,[Expr1009],0)))
其实就是做了一下类型转换。
然后,内侧操作的结果会保存到外侧的那行中,说白了就是把London的第一个消费者的订单数量存在这个消费者对象之中。
那么是不是当所有的嵌套循环执行完成后,形成了一个由(消费者,该消费者的订单个数)这样的结构所组成的数组呢?答案是否定的,因为计划中的分支是交叉执行的。当一个消费者完成了数数的工作,也完成他自己在前4步的操作,进入左上角的计算标量运算符中。
那么然后,由左上角的计算标量来处理这个数据,这个步骤就是做了一下值的检查:
|--Compute Scalar(DEFINE:([Expr1004]=CASE WHEN [Expr1004] IS NULL THEN (0) ELSE [Expr1004] END))
这里的[Expr1004]在之前已经定义过,还记得吧,首先是求某一个消费者的所有订单数,然后把值做了类型转换。这里又增加了一些判断:如果[Expr1004]是NULL则返回0,否则则执行之前的[Expr1004]。
接着,将结果传递给筛选器运算符。
文本形式的执行计划输出:
|--Filter(WHERE:([Expr1004]>(5)))
这里很好理解,就是对这条数据进行谓词操作,如果值不为真,则移除掉该数据。
终于,数据到达了排序运算符。大家应该可以想到,在所有要被排序的行全部就绪之前进行排序是没有意义的,因此这些行会在排序这一步进行等待,也就是说如果对Customers表的索引查找操作又找到一个来自London的消费者,将重复执行上述过程,直到所有要返回的行到达了排序运算符后,将按正确的顺序返回这些行。

文本形式的执行计划输出:
|--Sort(ORDER BY:([Expr1004] ASC))
