
改进的脏话审查方案
导言
我经常光顾cnbeta,那里的评论很精辟,有时我也会忍不住评上两句,但近来突然发现发布评论都必须经过审核才会显示了,这让我感到非常扫兴。由此我又想起了此前我曾讨论过的“非法内容核查方法”,我想这种人机结合的审核方式应该会比较适合现在的cnbeta吧。
而现在我已经对此方案有了更深、更好的思路了,想在此分享出来,和大家探讨一下,我将在此逐步解析整个审查的流程:
准备工作
要审查脏话,首先需要创建对应的审查规则,每条规则需要提供以下基本信息:
1. 表达式:用于审查内容是否匹配的正则表达式。使用正则的原因在于其灵活性,常规的纯文本检索虽然快,但遇到干扰符等情况时束手无策,而正则就可以轻松解决,例如表达式“[煞傻妈狗屎贱骚瘙搔臊][\s\S]{0,4}?[逼笔比BB鼻X]”可以匹配多种组合的脏话,并可兼容至多4个干扰字符。
2. 首字符列表:用于遍历文章内容时提取疑似首字符使用。对于表达式“[煞傻妈狗屎贱骚瘙搔臊][\s\S]{0,4}?[逼笔比BB鼻X]”来说,它的首字符列表中应包含“煞傻妈狗屎贱骚瘙搔臊”。
3. 尾字符列表:用于遍历文章内容时提取疑似尾字符使用。对于表达式“[煞傻妈狗屎贱骚瘙搔臊][\s\S]{0,4}?[逼笔比BB鼻X]”来说,它的尾字符列表中应包含“逼笔比BB鼻X”。
4. 分值:即匹配成功后,为该文章增加的危险度分值。
5. 最大长度:就是脏话内容可能出现的最大字数。对于表达式“[煞傻妈狗屎贱骚瘙搔臊][\s\S]{0,4}?[逼笔比BB鼻X]”来说,它的最大长度应当是6。
6. 精确长度:就是当脏话内容完全无干扰符的情况下的实际字数。此属性可以用于计算匹配内容的精准程度,比如还是用上面那个表达式“[煞傻妈狗屎贱骚瘙搔臊][\s\S]{0,4}?[逼笔比BB鼻X]”的例子,如果遇到语段“她的妈妈总是逼我们尽快完婚”也会匹配成功,但匹配到的内容长度会是5,与精确长度2进行比对的话,就可以得知此匹配项有可能属于误判;而且我们还可以让程序依据精确程度为文章打分,比如此规则原始分值为10分,但只有40%的精确度,那么在加分时可以只加4分,这样得出的危险度分值将更具参考性。
尽管主要目的是为了检验脏话,但此机制也完全适用于检验文章内的广告、色情、血腥、政治、宗教等内容,甚至还可能用来给内容做积极方面的评分,比如用以审阅学生作文,对特定修辞手法予以加分。
初始化
在审查之前,需要事先载入先前创建的规则,并加以分类,以更方便及加速检索。
分类的方法是建立一个Dictionary<规则>>类型的对象称为规则字典,将规则可能触发的首尾字符组合作为规则字典的键值,保存规则到对应的字典内的List中,这样可以极大地提高检索时获取规则的速度。
比如规则的首尾字符分别为“王”和“蛋”,那么就将此规则存入规则字典[“王蛋”]内的List中去,如果此规则存在多种首尾字符组合,那么就保存多个副本到各种首尾组合的规则字典键值中。
在分类的同时,还应该采集并创建以下数据,并保存备用:
1. 全局最大长度:即所有规则中,最大长度属性的最大值。此属性将用在检索时进行预判断,以减少不必要的遍历次数,提高效率。
2. 全局首字符列表:即所有规则中出现的首字符总列表。此属性用于检索文章全文时使用。
3. 全局尾字符列表:即所有规则中出现的尾字符总列表。此属性用于检索文章全文时使用。
遍历内容全文
遍历内容的每一个字符,依据全局首字符列表和全局尾字符列表找出可能是非法内容首字符或尾字符的字符,将该字符及其位置存入相应列表中,我们在这里将捕获到的列表称为疑似首字符列表及疑似尾字符列表。
这里我建议在捕获到尾字符时倒序插入到疑似尾字符列表中,这样在遍历匹配时可以优先匹配字符较多的内容,比如“傻”和“傻瓜”都符合脏话规则的情况下,优先匹配“傻瓜”。
分析并处理捕获内容
接着遍历疑似首字符列表,从疑似尾字符列表中找出可能与之搭配的尾字符(根据当前首字符索引位置及规则的全局最大长度进行预筛检:尾字符索引位置>=首字符索引位置&&尾字符索引位置<=首字符索引位置+全局最大长度)。
再将当前的首尾字符组合成字符串,当作键值,向规则字典查询键值内可能匹配的规则(根据当前首尾字符索引位置进行预筛检:规则最大长度>=尾字符索引位置-首字符索引位置+1)。
从原文中截取首字符索引位置到尾字符索引位置之间的片段,用当前规则进行检验,如匹配成功则依据匹配的精确度增加相应比例的分值(算法就是使用规则的精确长度除以实际捕获到的文本内容长度,再乘以规则的分值),然后开始检验跨过当前尾字符索引位置之后的下一个首字符。
除了输出累计评分外,还可以在审核时生成最高评分、平均精确度、危险内容覆盖比例等信息,供人工审核时参考。
总结
依照上述步骤,即完成了整个机审过程,然后就可以根据评分结果来决定如何处理文章了。整个过程的简略的流程示意图如下:
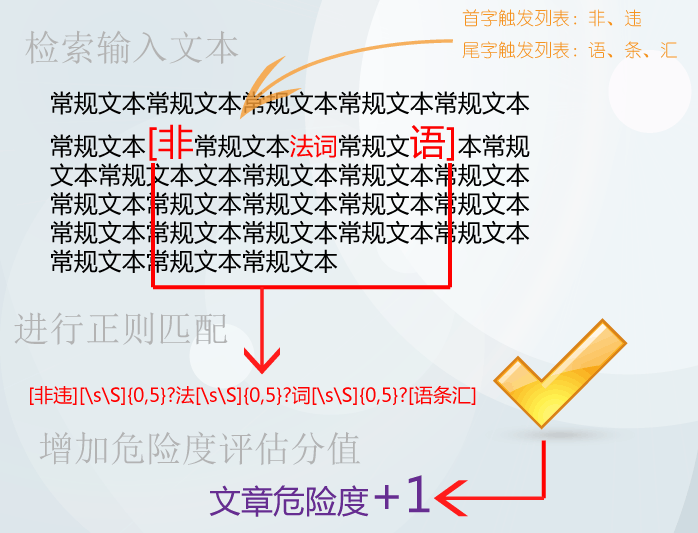
这个经过改进的方案兼顾了性能与灵活性:只进行一次全文扫描;使用正则表达式进行语段匹配。预计稍加优化,并加入缓存机制的话,常规文章的审核耗时不会超过半秒。
存在并期待改进的缺点:由于采用了首尾字符匹配形式触发正则验证,正则中的断言似乎就无用武之地了,这使得正则发挥的功能有所缩减,鱼与熊掌真不可兼得吗?
最后,再重申一下我对人机协作审核机制的处理建议:
不要尝试将危险文字自动替换后直接发布,省去人工审核,那样只会招致无限的道魔战。
无危险的内容应直接发布;
有一定危险的内容也会发布,但在发布的同时会在后台提请管理员进行人工审查;
高危险度的内容延迟发布并通知管理员。
我的想法就说到这里了,欢迎大家回复交流。
声明:此方案参考并借鉴了Sumtec的字符串多模式精确匹配(脏字/敏感词汇搜索算法)——TTMP算法 之理论如此一文中的部分算法思路,在此深表感谢。
下载本文的PDF版本:http://uushare.com/user/icesee/file/1387050
