
在线数据迁移经验:如何为正在飞行的飞机更换引擎
在线数据迁移,是指将正在提供线上服务的数据,从一个地方迁移到另一个地方,整个迁移过程中要求不停机,服务不受影响。根据数据所处层次,可以分为cache迁移和存储迁移;根据数据迁移前后的变化,又可以分为平移和转移。
平移是指迁移前后数据组织形式不变,比如Mysql从1个实例扩展为4个实例,Redis从4个端口扩展到16个端口,HBase从20台机器扩展到 30台机器等等。如果在最初的设计里就为以后的扩容缩容提供了方便,那么数据迁移工作就会简单很多,比如Mysql已经做了分库分表,扩展实例的时候,只需要多做几个从库,切换访问,最后将多余的库表删除即可。更进一步,在实现上已经做到全自动数据迁移,如 HBase,就更简单了:添加机器,手工修改配置或者系统自动发现,然后,沏一杯咖啡,等待系统完成迁移。
转移是指数据迁移前后,数据组织形式发生了变化。多年前,某社交平台曾经为ID升级做过一次数据迁移,将ID由最初的自增算法修改为巧妙设计的UUID算法,这次迁移最大的挑战是要修改数据的主键,主键本来是数据的唯一标识,它发生变化,也就意味着原来的数据不复存在,新的数据凭空产生,对于整个系统中所有业务流程、周边配套、上下游部门都会产生巨大的兼容性挑战。不过大部分数据迁移项目都不会修改主键,甚至不会修改数据本身,改变的只是数据的组织形式。比如某社交平台计数器原本为了节约存储空间,使用redis hash进行存储,后来为了提升批量查询的性能,迁移成 KV 形式;又比如某社交平台的转发列表和粉丝列表,最初都使用Mysql存储,后来为了更好的扩展性和成本,都迁移到HBase存储。
在线数据迁移最大的挑战是如何保证迁移过程服务不受影响。很多人将其比喻成“飞行过程中换发动机”“给行驶的汽车换轮胎”,但实际上并没有那么困难,一个入行一两年的技术人员,遵从一些经验指导,完全可以完成。下面就跟大家分享一下个人在这方面的一些经验,作为抛砖引玉。
在线数据迁移一般分为四个步骤:一,上线双写,即同时写入新旧两种数据;二,历史数据离线搬迁,即离线将历史存量数据从旧系统搬到新系统;三,切读,即将读请求路由到新系统;四,清理沉淀,包括清理旧的数据,回收资源,及清理旧的代码逻辑,旧的配套系统等等,将迁移过程中的经验教训进行总结沉淀,将过程中开发或使用的工具进行通用化改造,以备下次使用。注意,某些情况下,步骤一和步骤二也可能倒过来,先做历史数据搬迁,然后再写入新数据,这时候就需要谨慎的处理搬迁这段时间里产生的新数据,一般使用 queue 缓存写入的方式,称为“追数据”。

图1:在线数据迁移步骤示意图
下面以某社交平台粉丝列表从Mysql迁移到HBase为例子,展开来讲讲每个步骤具体实施、可能的问题及对策。
在迁移之前,根据以往的经验制定了更详细的流程,如图:
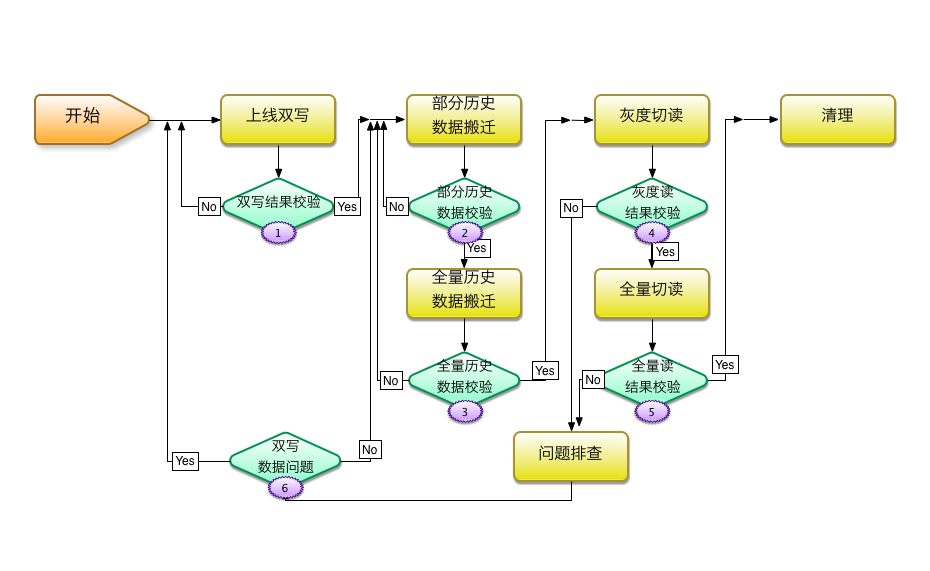
图2:粉丝列表迁移到HBase工作流程图
上线双写
编写双写的代码逻辑之前,首先要根据业务规则和性能指标确定HBase的表结构和主键设计。
对于列表类的需求,HBase有两种典型的用法,一种是高表模式,与传统的Mysql模式非常类似,列表中的每一项存一行,每一行有固定的属性列;另一种是宽表模式,一个列表存一行,列表中的每一项存成一个单独的列,各种属性都打包到列内部的value中。如图:

图3:粉丝列表业务分别使用HBase高表模式和宽表模式存储示意图
高表模式的好处在于与Mysql类似,各种业务逻辑的实现也比较像,认知和改造成本较低,劣势在于因为HBase的实现机制导致单个列表可能被分别存储在多个不同的Region里,查询的性能较差。而宽表的优劣势正好与高表相反。在高并发大流量系统中,技术方案很多特性都可以妥协,但唯独性能永远是不能妥协的,所以我们选择宽表模式。
很多高并发系统都采用上行异步化,通过将操作转化为消息,写入消息队列,后台异步处理的方式来削峰填谷,并获得更好的可用性。大部分消息队列都支持单个消息被多个业务模块重复处理,并支持串联和并联。所以在这里我们将写入HBase的代码逻辑单独封装到一个模块中,将它配置为与写入旧Mysql代码串联或并联即可。
为了支持消息异步处理的重试机制,建议将业务模块设计成具有幂等特性,即同一条消息可以重试多次,而不会破坏最终的结果。有一些模块,如计数器,提醒等,业务本身不支持重试,可以通过“重复消息检测模块”为它们提供短时间内的重试支持。大部分Mysql存储都通过主键或者单独的Unique key索引来达到幂等要求,相应的,HBase高表模式通过主键保证,宽表模式通过column qualifier保证。在粉丝列表迁移过程中,因为column qualifier不能保证幂等,导致数据一致性无法达到要求,最后也是通过引入额外的重复消息检测模块解决。
另外,HBase当前不提供二级索引、覆盖索引、join、order by等Mysql高级查询功能,需要在迁移之前做好评估,确定新方案能够支持所有的业务特性。比如粉丝列表一般都是查询最新的5000个粉丝,但如果还要支持查询最初100个粉丝列表的功能,就会比较费劲。
上线双写完成后,需要对双写的数据进行一致性校验。数据一致性校验需要从两个维度进行:存储维度和业务维度。存储维度是指直接取Mysql和HBase里的数据进行对比;业务维度是指从最终用户看到的数据维度进行校验,即访问粉丝列表页面,看结果是否与原来一致。大型系统的数据一致性校验建议及格线是6个9,即99.9999%,也就是说每一百万条数据中,差别不能超过1条。
历史数据搬迁
上线双写并校验确认通过后,就可以开始搬迁历史数据了。
搬迁历史数据的步骤中,最大的困难是保证搬迁过程与线上业务写入互不干扰。对于列表类功能,最大的干扰是来自于这样一种业务场景:搬迁程序从Mysql中select出来一个列表,在插入到HBase之前,这个列表发生了变化。如果是增加一个元素,由于HBase的幂等保证,最终结果并不会产生偏差,但如果是删除一个或多个元素,那么最终会表现为HBase中删除操作未生效,因为线上业务执行完删除操作后,搬迁程序又执行了插入操作。本质上,这是因为我们在这样的数据量规模下不能使用事务引起的,如果引入事务,能够解决这个问题,但同时也会将搬迁耗时从几天延长到几周甚至几个月。为了解决这个问题,可以通过引入轻量级的Memcache锁来模拟Serializable级别的事务隔离。
历史数据搬迁完成后也需要进行一致性校验。实际上,建议在搬迁全量数据之前,先搬迁部分数据,并进行一致性校验。部分数据一致性校验通过后,再对全量数据进行搬迁。这种方式可以极大的节约搬迁时间,降低因为搬迁流程或代码不完善导致的延期风险。
切读
全量数据搬迁并校验完成后,即可以进行读请求切换了。通用的切换方式是在代码中埋入开关,通过 Config Service 或类似机制进行切换操作。切换的流程为:Tcpcopy环境 --> 线上环境 uid 白名单(内部工程师)--> 线上环境百分比灰度 0.01%,1%,10% --> 线上环境全量。tcpcopy 环境用来验证代码在线上环境是否正常,uid白名单用来验证功能是否正常,百分比灰度用来验证性能和资源压力是否正常,所有验证都通过后,最后才进行全量切换。一般这个过程会持续一周到两周。
清理沉淀
切读完成后,整个数据迁移过程可以认为已经完成了。但项目工作并没有完结,旧的逻辑代码清理,旧的配套系统下线,旧资源回收,以及最重要的一个环节:经验教训总结、分享,流程完善,工具通用化改造。
在线数据迁移并不是一项需要高深技术的工作,它更多需要的是对业务逻辑的把控,对操作流程的理解,对新旧系统特性的掌握,以及对细节的敬畏之心。